ANALYSES TELLi
Cetta page a pour but de présenter un ensemble de méthodes de statistiques (corrélation, ACP, modèle de régression)
HDF-AUV_LIM (min_max)
1 - Analyse des données
Nous cherchons à étudier les liens entre la fréquentation voyageurs 2022 des gares SNCF situées dans les Hauts-de-France (carte 1) et dans les anciennes régions Auvergne et Limousin (carte 2) avec un ensemble de variables quantitatives.
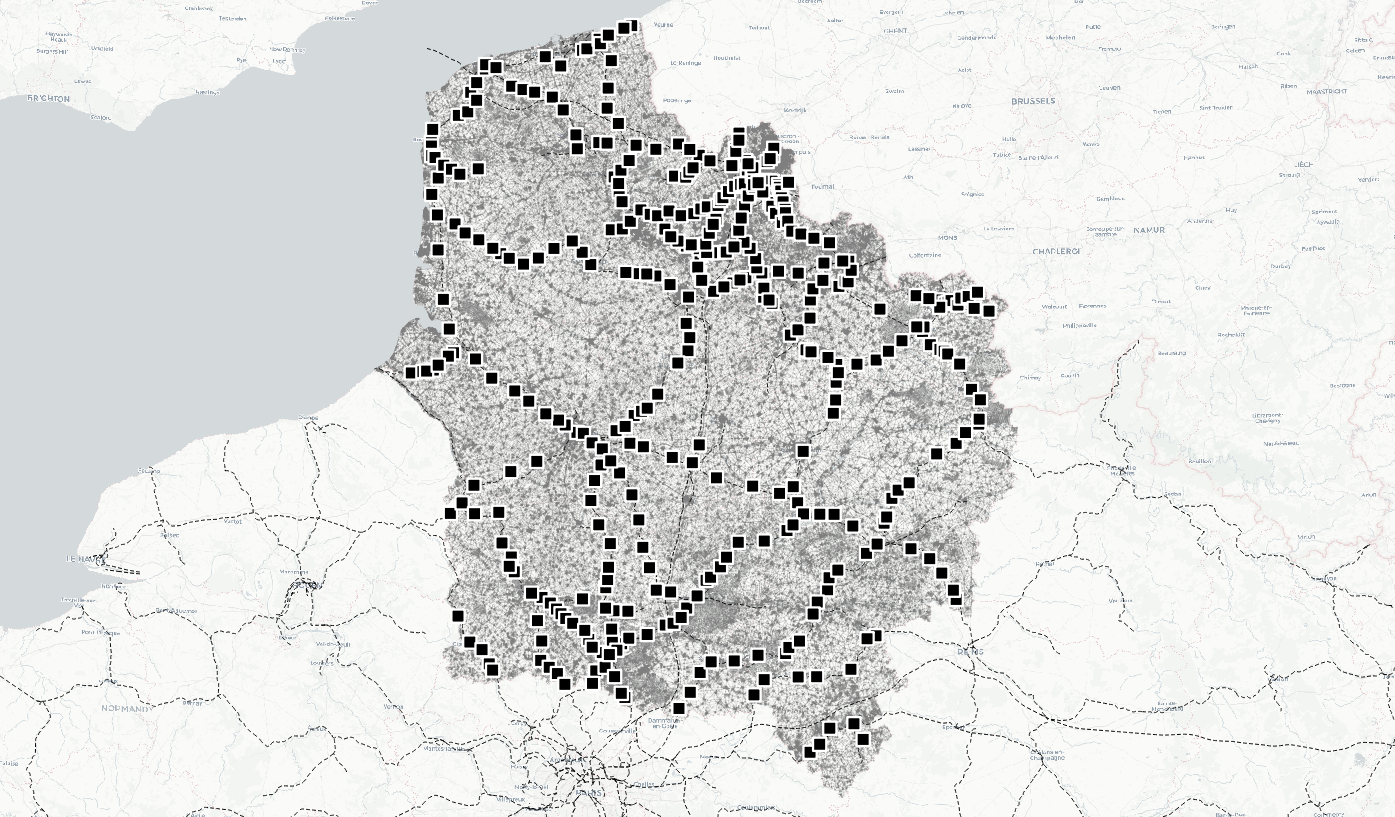 Carte 1 : Cartographie des gares
dans la région des Hauts-de-France
Carte 1 : Cartographie des gares
dans la région des Hauts-de-France 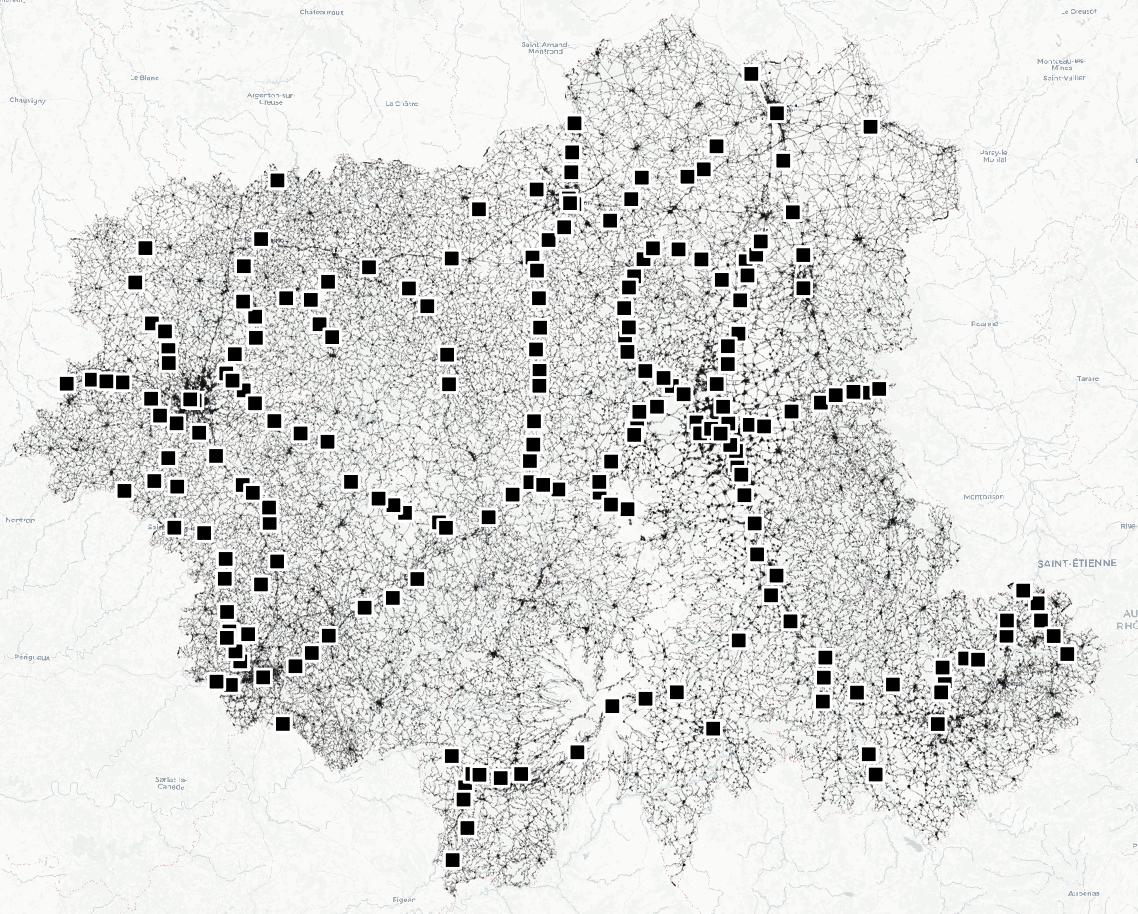 Carte 2 : Cartographie des
gares des anciennes régions Auvergne et Limousin
Carte 2 : Cartographie des
gares des anciennes régions Auvergne et Limousin pacman::p_load(sf, tmap, dplyr, mapview, FactoMineR, factoextra,
performance, # analyser les modèles statistiques
ggplot2, dbscan, broom.helpers, car, factoextra, coorplot
)## Installation du package dans 'C:/Users/oliviertheureaux/AppData/Local/R/win-library/4.5'
## (car 'lib' n'est pas spécifié)## Warning: le package 'coorplot' n'est pas disponible for this version of R
##
## Une version de ce package pour votre version de R est peut-être disponible ailleurs,
## Voyez des idées à
## https://cran.r-project.org/doc/manuals/r-patched/R-admin.html#Installing-packages## Warning: impossible d'accéder à l'index de l'entrepôt http://www.stats.ox.ac.uk/pub/RWin/bin/windows/contrib/4.5:
## impossible d'ouvrir l'URL 'http://www.stats.ox.ac.uk/pub/RWin/bin/windows/contrib/4.5/PACKAGES'## Warning in p_install(package, character.only = TRUE, ...):## Warning in library(package, lib.loc = lib.loc, character.only = TRUE,
## logical.return = TRUE, : aucun package nommé 'coorplot' n'est trouvé## Warning in pacman::p_load(sf, tmap, dplyr, mapview, FactoMineR, factoextra, : Failed to install/load:
## coorplotPour cela nous disposons des variables suivantes. Ces variables ont été calculées pour chaque isochrone de 10 minutes à pied autour de chaque gare.
all_data_hdf <- sf::st_read('processed_data/all_data_region_HDF_foot_10min_20240319_min_max.gpkg') %>%
dplyr::select(-c(ID, reseau_pedestre, pop_p15_2017))## Reading layer `all_data_region_HDF_foot_10min_20240319_min_max' from data source `C:\docs\rprojects\database_sf\processed_data\all_data_region_HDF_foot_10min_20240319_min_max.gpkg'
## using driver `GPKG'
## Simple feature collection with 393 features and 24 fields
## Geometry type: POINT
## Dimension: XY
## Bounding box: xmin: 595141.4 ymin: 6874373 xmax: 781232.5 ymax: 7108435
## Projected CRS: RGF93 v1 / Lambert-93## [1] "ID_number" "voy_2022"
## [3] "sum_population" "sum_population_active"
## [5] "sum_lits" "longueur_route"
## [7] "nb_intersections" "longueur_pistes_cyclables"
## [9] "nombre_arrets" "nombre_parkings"
## [11] "nombre_commerces" "nombre_sante"
## [13] "nombre_loisirs" "nombre_restauration"
## [15] "nombre_sports" "nombre_ronds_points"
## [17] "nombre_eleves" "ZA"
## [19] "passage_niveau" "sum_population_carreau"
## [21] "PNR_OK" "geom"all_data_auv_lim <- sf::st_read('processed_data/all_data_region_Auv_Lim_foot_10min_20240319_min_max.gpkg')## Reading layer `all_data_region_Auv_Lim_foot_10min_20240319_min_max' from data source `C:\docs\rprojects\database_sf\processed_data\all_data_region_Auv_Lim_foot_10min_20240319_min_max.gpkg'
## using driver `GPKG'
## Simple feature collection with 209 features and 21 fields
## Geometry type: POINT
## Dimension: XY
## Bounding box: xmin: 530264.7 ymin: 6401103 xmax: 805938 ymax: 6617711
## Projected CRS: RGF93 v1 / Lambert-93## [1] "ID_number" "voy_2022"
## [3] "sum_population" "sum_population_active"
## [5] "sum_lits" "longueur_route"
## [7] "nb_intersections" "longueur_pistes_cyclables"
## [9] "nombre_arrets" "nombre_parkings"
## [11] "nombre_commerces" "nombre_sante"
## [13] "nombre_loisirs" "nombre_restauration"
## [15] "nombre_sports" "nombre_ronds_points"
## [17] "nombre_eleves" "ZA"
## [19] "passage_niveau" "sum_population_carreau"
## [21] "PNR_OK" "geom"Nombre de voyageurs total
## [1] 124037704Top 10 des gares
## Simple feature collection with 10 features and 2 fields
## Geometry type: POINT
## Dimension: XY
## Bounding box: xmin: 650564.5 ymin: 6519931 xmax: 736844.4 ymax: 7060255
## Projected CRS: RGF93 v1 / Lambert-93
## nom_gare voy_2022 geom
## 1 Lille Flandres 21992946 POINT (704951.3 7059959)
## 2 Lille Europe 6056899 POINT (705371 7060255)
## 3 Amiens 6004673 POINT (650564.5 6977107)
## 4 Creil 5224702 POINT (661361.1 6907253)
## 5 Clermont Ferrand 4095262 POINT (707812.6 6519931)
## 6 Arras 3920113 POINT (684439.8 7020999)
## 7 Douai 2964246 POINT (706410.5 7030449)
## 8 Valenciennes 2875726 POINT (736844.4 7029628)
## 9 Chantilly-Gouvieux 2600290 POINT (660614.6 6898746)
## 10 Compiègne 2341622 POINT (687203.1 6924742)## Rows: 602
## Columns: 22
## $ ID_number <chr> "Pont de la Deûle", "Outreau", "Sous le Bois…
## $ voy_2022 <dbl> 24168, 0, 8, 554, 513226, 1989, 238, 3920113…
## $ sum_population <dbl> 0.1751477517, 0.0601894551, 0.1192634891, 0.…
## $ sum_population_active <dbl> 0.1507132358, 0.0541060553, 0.0942287243, 0.…
## $ sum_lits <dbl> 0.0329117367, 0.0072079423, 0.0425676595, 0.…
## $ longueur_route <dbl> 0.343967986, 0.006168987, 0.296963409, 0.219…
## $ nb_intersections <dbl> 0.27310924, 0.00000000, 0.25315126, 0.228991…
## $ longueur_pistes_cyclables <dbl> 0.036460243, 0.000000000, 0.000000000, 0.057…
## $ nombre_arrets <dbl> 0.088000000, 0.000000000, 0.005333333, 0.005…
## $ nombre_parkings <dbl> 0.0001071123, 0.0000000000, 0.0002142245, 0.…
## $ nombre_commerces <dbl> 0.004201681, 0.000000000, 0.018907563, 0.000…
## $ nombre_sante <dbl> 0.106796117, 0.000000000, 0.009708738, 0.000…
## $ nombre_loisirs <dbl> 0.01176471, 0.00000000, 0.03529412, 0.000000…
## $ nombre_restauration <dbl> 0.007984032, 0.000000000, 0.013972056, 0.001…
## $ nombre_sports <dbl> 0.00000000, 0.00000000, 0.00000000, 0.000000…
## $ nombre_ronds_points <dbl> 0.2, 0.0, 0.1, 0.2, 0.6, 0.3, 0.0, 0.2, 0.0,…
## $ nombre_eleves <dbl> 0.0000000, 0.0000000, 0.0000000, 0.0000000, …
## $ ZA <dbl> 0.3966329, 0.1188995, 0.4081313, 0.3235975, …
## $ passage_niveau <dbl> 0.1666667, 0.0000000, 0.0000000, 0.0000000, …
## $ sum_population_carreau <dbl> 0.2364492977, 0.0098190304, 0.1871339879, 0.…
## $ PNR_OK <dbl> 0, 1, 0, 1, 0, 1, 0, 0, 0, 1, 0, 0, 0, 0, 0,…
## $ geom <POINT [m]> POINT (706054.2 7033395), POINT (60171…
Boxplots des données
data_all_boxplot <- all_data %>%
dplyr::select(sum_population, sum_population_active, sum_lits, longueur_route,
nb_intersections, longueur_pistes_cyclables,
nombre_arrets,nombre_parkings, nombre_commerces,nombre_sante,
nombre_loisirs, nombre_restauration, nombre_sports,
nombre_ronds_points, nombre_eleves, ZA, passage_niveau,
sum_population_carreau, PNR_OK) %>%
st_drop_geometry()boxplot(data_all_boxplot, main = "Données HDF 10 min à pied",
las = 2) # Rotate labels by 90 degrees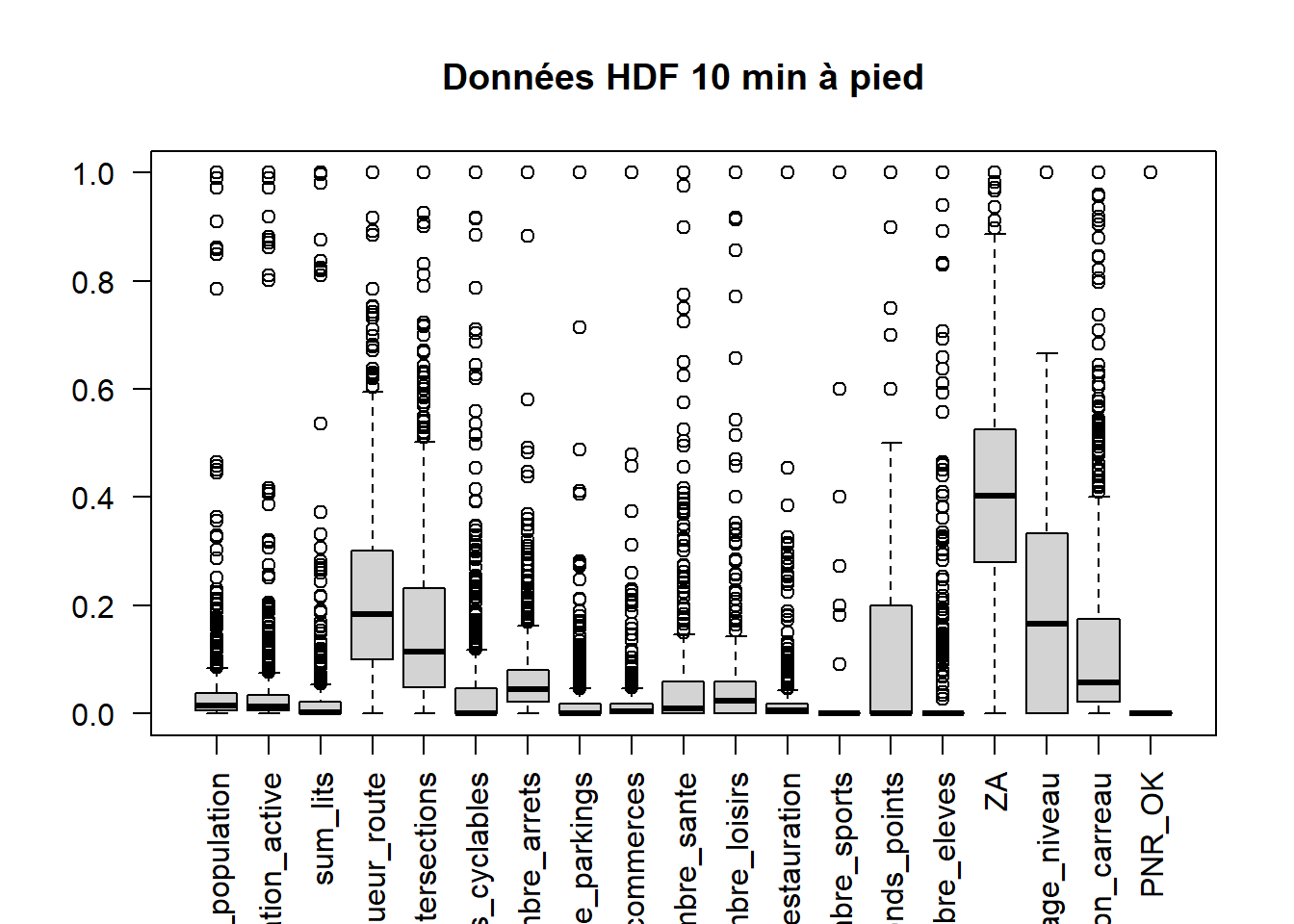
Distribution de la variable dépendante
hist(all_data$voy_2022,
freq=T,
breaks = 100,
col = "darkblue",
border = "white",
main = "Voyageurs 2022 Hauts-de-France")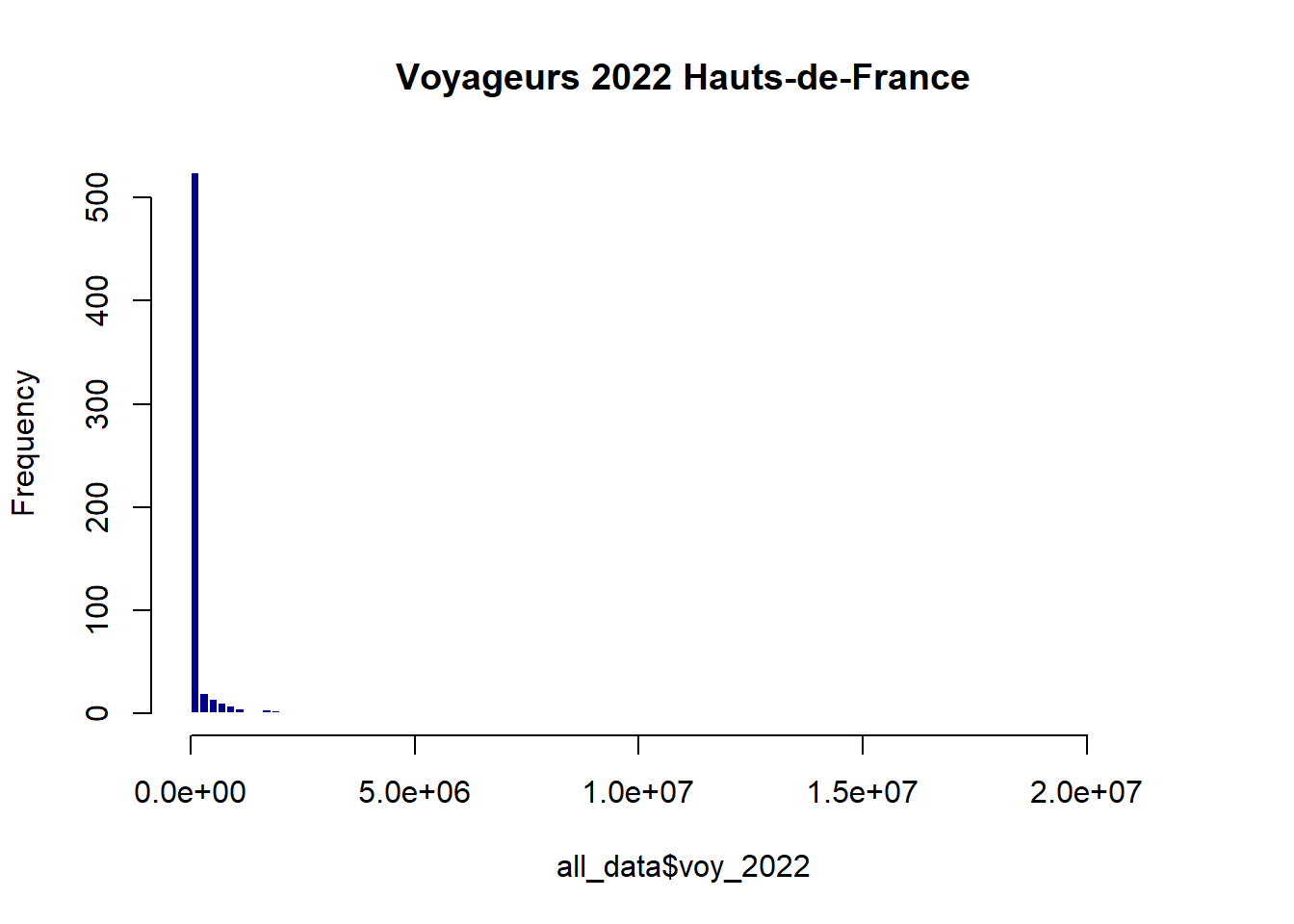
Détection des outliers avec DBScan
library(dbscan) dbscan_result <- dbscan(all_data, eps = 5, minPts = 8) dbscan_result
Suppression des valeurs aberrantes: gares >= à 10 voyageurs par an et inf à 10 000 000
Appliquer une transformation logarithmique à la variable dépendante
Transformation logarithmique : Elle est particulièrement utile pour les données qui suivent une distribution exponentielle ou log-normale. La transformation peut aider à stabiliser la variance des résidus et à rendre les relations entre les variables plus linéaires, ce qui est souhaitable dans la régression linéaire.
Distribution de la variable dépendante transformée
hist(all_data_filter$log_voy_2022,
freq=T,
breaks = 100,
col = "darkblue",
border = "white",
main = "Voyageurs 2022 Hauts-de-France")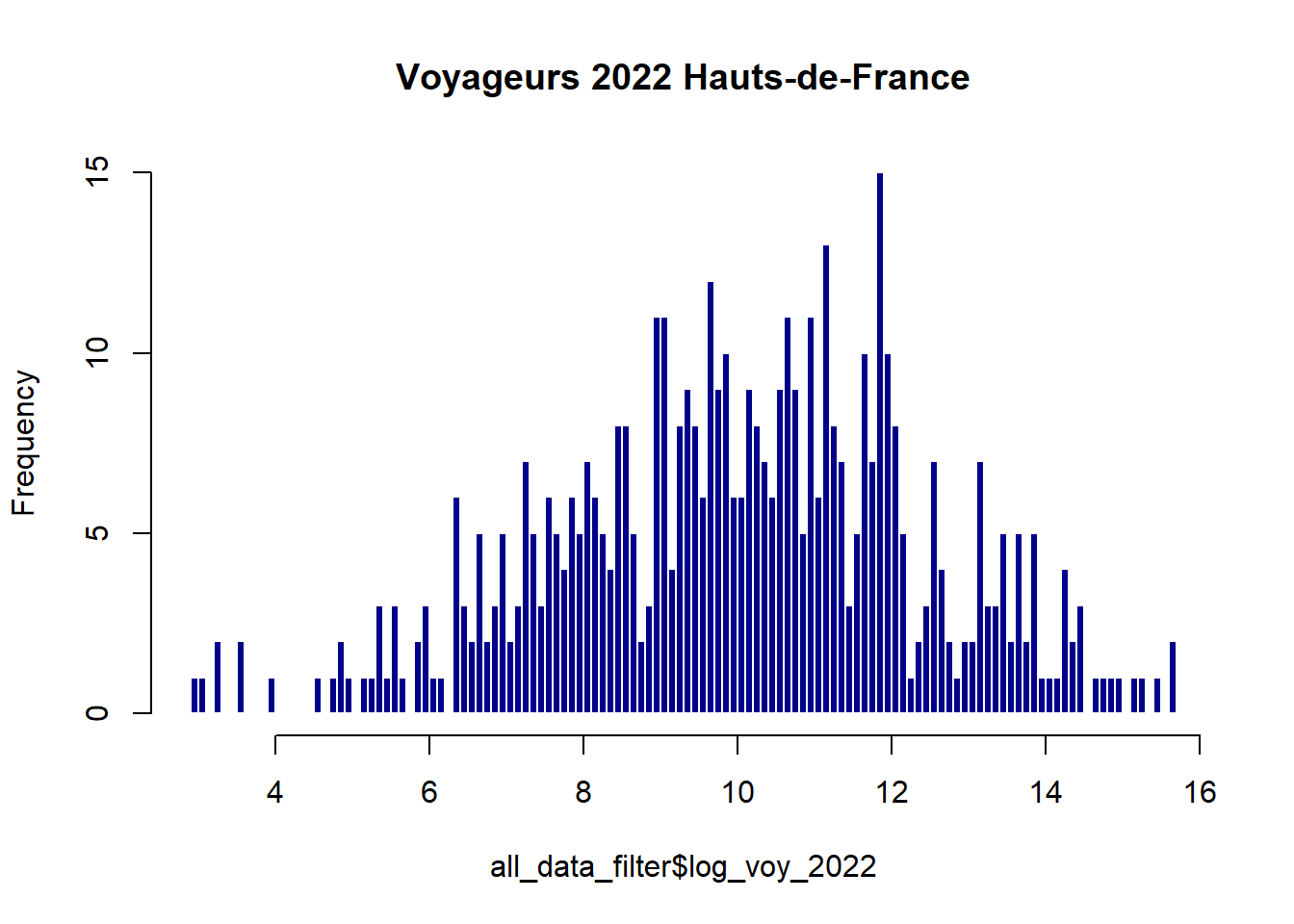 Normalité de la variable dépendante
Normalité de la variable dépendante
La variable dépendante voy_2020 suit bien une loi normale (p_value > 0.05)
##
## Shapiro-Wilk normality test
##
## data: all_data_filter$log_voy_2022
## W = 0.9941, p-value = 0.05065Matrice de corrélation
data_for_cor <-
all_data_filter[, c(
"log_voy_2022",
"sum_population",
"sum_population_active",
"sum_lits",
"longueur_route",
"nb_intersections",
# "reseau_pedestre" ,
"longueur_pistes_cyclables",
"nombre_arrets",
"nombre_parkings",
"nombre_commerces",
"nombre_sante",
"nombre_loisirs",
"nombre_restauration",
"nombre_sports",
"nombre_ronds_points",
"nombre_eleves",
"ZA",
"passage_niveau",
"sum_population_carreau",
"PNR_OK"
)]
data_for_cor <- sf::st_drop_geometry(data_for_cor)
mcor <- cor(data_for_cor, use = "complete.obs")
corrplot::corrplot(mcor,
type="upper",
order="hclust",
tl.col="black")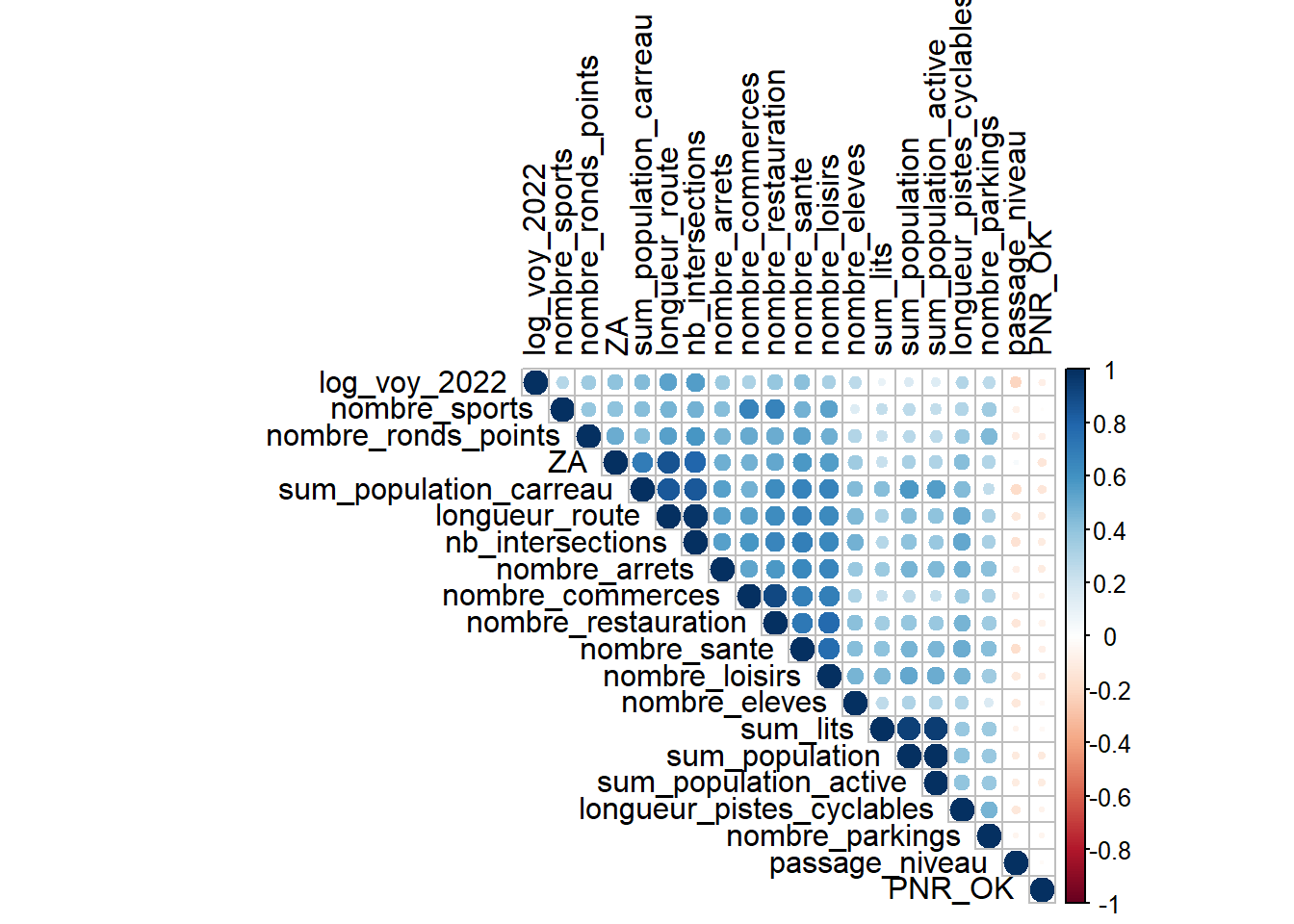
2 - Analyse en composantes principales (ACP)
L’analyse en composantes principales crée de nouvelles variables :
des facteurs ou des composantes. Les facteurs sont des combinaisons
linéaires des variables introduites. On cherche à réduire le nombre de
variables en ne conservant qu’une ou deux variables (composantes)
regroupant la variation la plus importante de l’ensemble des variables
introduites.
Les variables de chaque composante sont fortement corrélées.
En ne conservant que les variables les plus importantes de chaque
composante, on ne perd pas d’information mais on réduit le nombre de
variables.
## Rows: 498
## Columns: 23
## $ ID_number <chr> "Pont de la Deûle", "Les Bons-Pères", "Maube…
## $ voy_2022 <dbl> 24168, 554, 513226, 1989, 238, 3920113, 1494…
## $ sum_population <dbl> 0.1751477517, 0.0189921255, 0.1192634891, 0.…
## $ sum_population_active <dbl> 0.1507132358, 0.0174699951, 0.0942287243, 0.…
## $ sum_lits <dbl> 0.0329117367, 0.0000000000, 0.0425676595, 0.…
## $ longueur_route <dbl> 0.34396799, 0.21975495, 0.50399247, 0.296212…
## $ nb_intersections <dbl> 0.27310924, 0.22899160, 0.51995798, 0.279411…
## $ longueur_pistes_cyclables <dbl> 0.036460243, 0.057294562, 0.080591151, 0.000…
## $ nombre_arrets <dbl> 0.088000000, 0.005333333, 0.026666667, 0.064…
## $ nombre_parkings <dbl> 0.0001071123, 0.0000000000, 0.0502356470, 0.…
## $ nombre_commerces <dbl> 0.004201681, 0.000000000, 0.031512605, 0.008…
## $ nombre_sante <dbl> 0.106796117, 0.000000000, 0.019417476, 0.019…
## $ nombre_loisirs <dbl> 0.01176471, 0.00000000, 0.02352941, 0.047058…
## $ nombre_restauration <dbl> 0.007984032, 0.001996008, 0.059880240, 0.005…
## $ nombre_sports <dbl> 0.00000000, 0.00000000, 0.09090909, 0.000000…
## $ nombre_ronds_points <dbl> 0.2, 0.2, 0.6, 0.3, 0.0, 0.2, 0.0, 0.0, 0.2,…
## $ nombre_eleves <dbl> 0.0000000, 0.0000000, 0.0000000, 0.1255887, …
## $ ZA <dbl> 0.3966329, 0.3235975, 0.4251031, 0.5001756, …
## $ passage_niveau <dbl> 0.1666667, 0.0000000, 0.0000000, 0.6666667, …
## $ sum_population_carreau <dbl> 0.2364492977, 0.0875346748, 0.1503236317, 0.…
## $ PNR_OK <dbl> 0, 1, 0, 1, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0,…
## $ geom <POINT [m]> POINT (706054.2 7033395), POINT (77214…
## $ log_voy_2022 <dbl> 10.092785, 6.317165, 13.148472, 7.595387, 5.…data_select <- all_data_filter %>%
select(sum_population,
sum_population_active,
sum_lits,
longueur_route,
nb_intersections,
# reseau_pedestre,
longueur_pistes_cyclables,
nombre_arrets,
nombre_parkings,
nombre_commerces,
nombre_sante,
nombre_loisirs,
nombre_restauration,
nombre_sports,
nombre_ronds_points,
nombre_eleves,
ZA,
passage_niveau,
sum_population_carreau,
PNR_OK
) %>%
sf::st_drop_geometry()# Coefficient de corrélation de PEARSON
# Ces coefficients mesurent la force et la direction de la relation linéaire entre chaque paire de variables
stats::cor(data_select, use = "complete.obs")# Lancement de l'ACP
PCA <- FactoMineR::PCA(data_select,
quanti.sup = c(),
quali.sup = c("PNR_OK"), # valeur binaire traitée comme une variable supplémentaire
scale.unit = T) # normalisation des variables## Warning: ggrepel: 5 unlabeled data points (too many overlaps). Consider
## increasing max.overlaps## Warning in geom_bar(stat = "identity", fill = barfill, color = barcolor, :
## Ignoring empty aesthetic: `width`.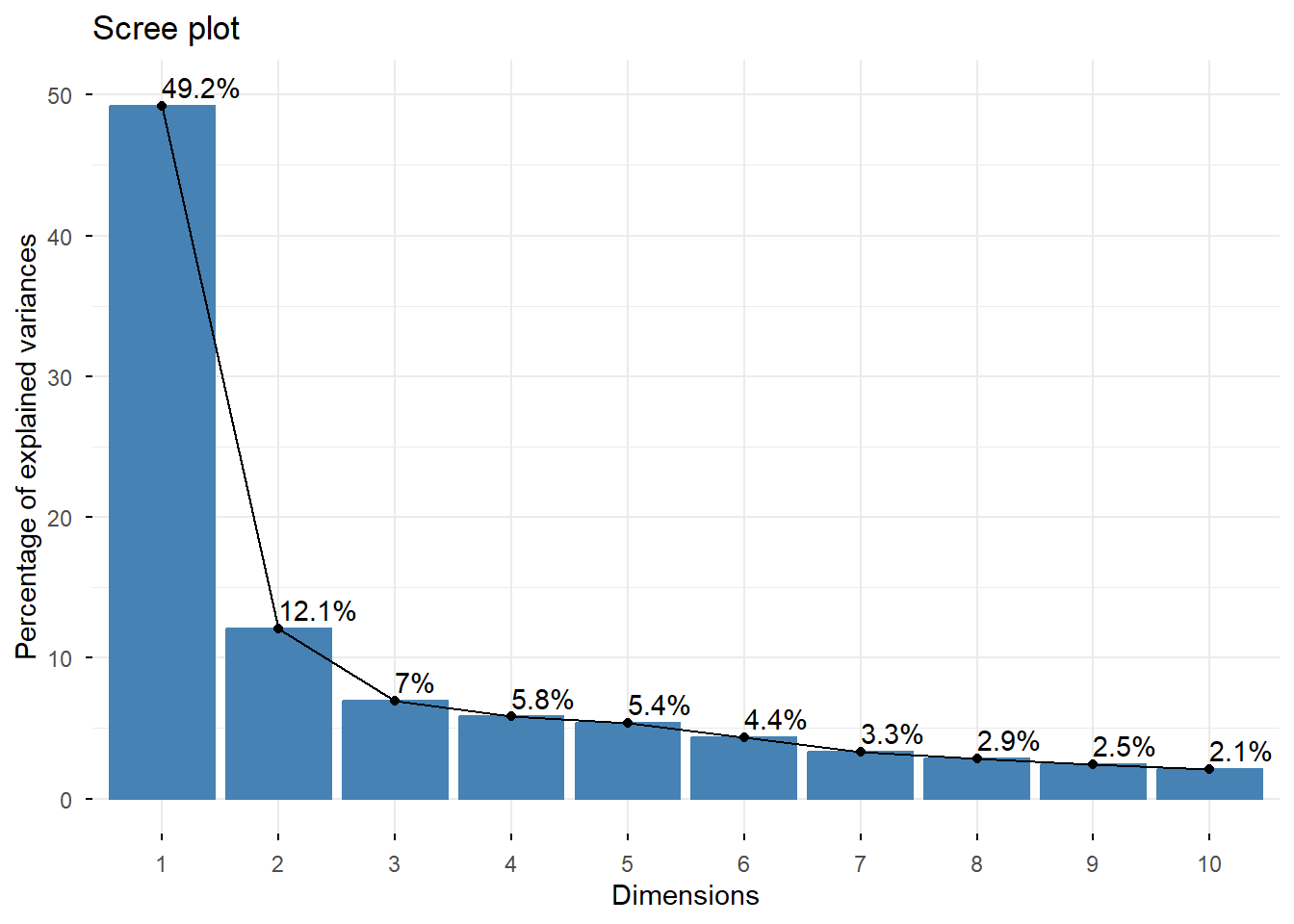
# Cercle des corrélations
factoextra::fviz_pca_var(PCA, col.var="contrib",
gradient.cols = c("#00AFBB", "#E7B800", "#FC4E07"),
repel = TRUE)## Warning: Using `size` aesthetic for lines was deprecated in ggplot2 3.4.0.
## ℹ Please use `linewidth` instead.
## ℹ The deprecated feature was likely used in the ggpubr package.
## Please report the issue at <https://github.com/kassambara/ggpubr/issues>.
## This warning is displayed once every 8 hours.
## Call `lifecycle::last_lifecycle_warnings()` to see where this warning was
## generated.## Warning: `aes_string()` was deprecated in ggplot2 3.0.0.
## ℹ Please use tidy evaluation idioms with `aes()`.
## ℹ See also `vignette("ggplot2-in-packages")` for more information.
## ℹ The deprecated feature was likely used in the factoextra package.
## Please report the issue at <https://github.com/kassambara/factoextra/issues>.
## This warning is displayed once every 8 hours.
## Call `lifecycle::last_lifecycle_warnings()` to see where this warning was
## generated.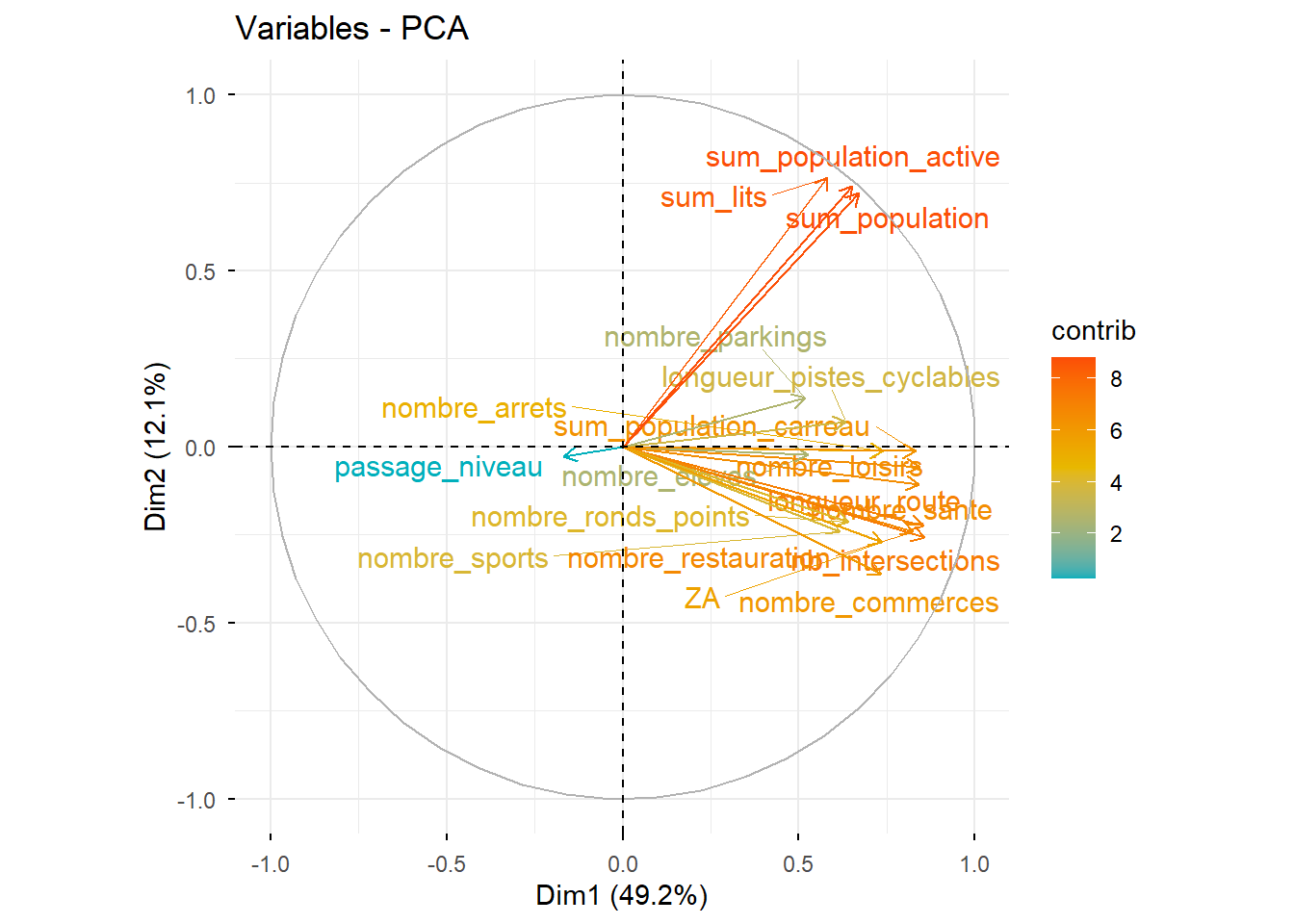
# Graphique des individus
factoextra::fviz_pca_ind(PCA, col.ind = "cos2",
gradient.cols = c("#00AFBB", "#E7B800", "#FC4E07"),
repel = TRUE)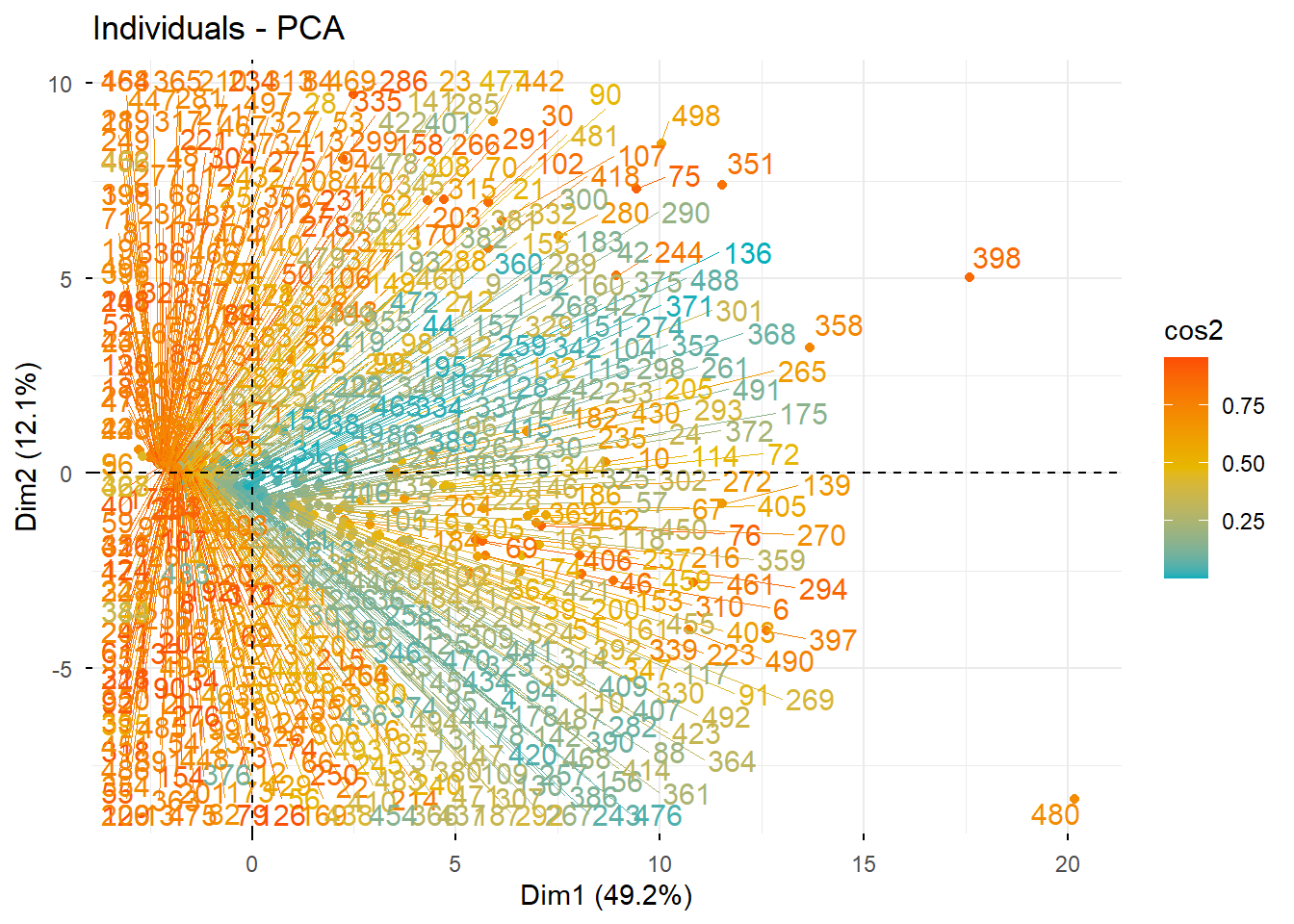
## eigenvalue percentage of variance cumulative percentage of variance
## comp 1 8.8559422411 49.19967912 49.19968
## comp 2 2.1720576319 12.06698684 61.26667
## comp 3 1.2543056661 6.96836481 68.23503
## comp 4 1.0487421884 5.82634549 74.06138
## comp 5 0.9687201918 5.38177884 79.44316
## comp 6 0.7871156908 4.37286495 83.81602
## comp 7 0.6008773341 3.33820741 87.15423
## comp 8 0.5148327296 2.86018183 90.01441
## comp 9 0.4424071786 2.45781766 92.47223
## comp 10 0.3817408373 2.12078243 94.59301
## comp 11 0.2605800218 1.44766679 96.04068
## comp 12 0.2365785625 1.31432535 97.35500
## comp 13 0.2192855151 1.21825286 98.57325
## comp 14 0.1254877157 0.69715398 99.27041
## comp 15 0.0678815424 0.37711968 99.64753
## comp 16 0.0482203956 0.26789109 99.91542
## comp 17 0.0144787432 0.08043746 99.99586
## comp 18 0.0007458138 0.00414341 100.00000# Contribution de chaque variable aux deux premiers axes
factoextra::fviz_contrib(PCA, choice = "var", axes = 1) # axe 1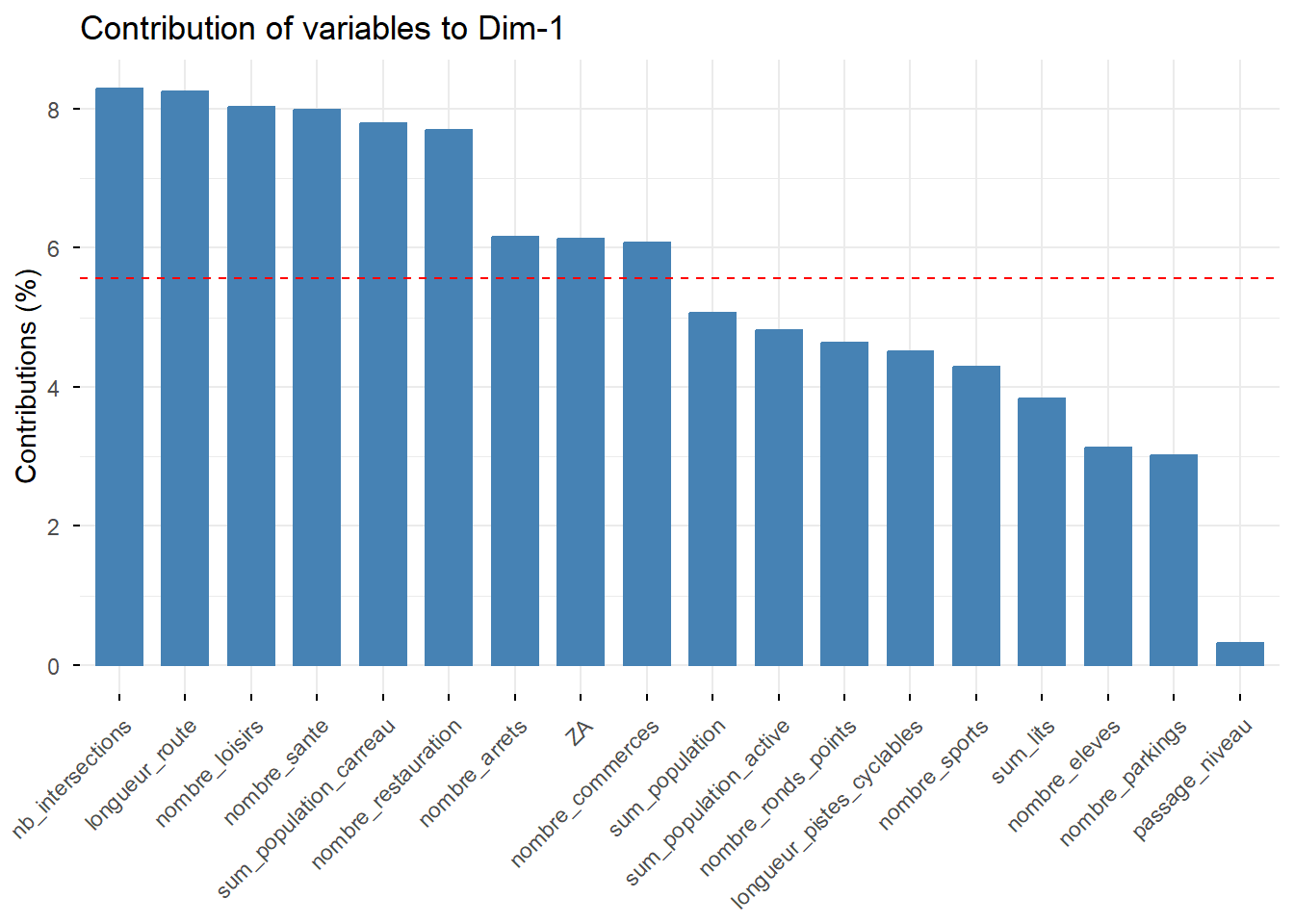
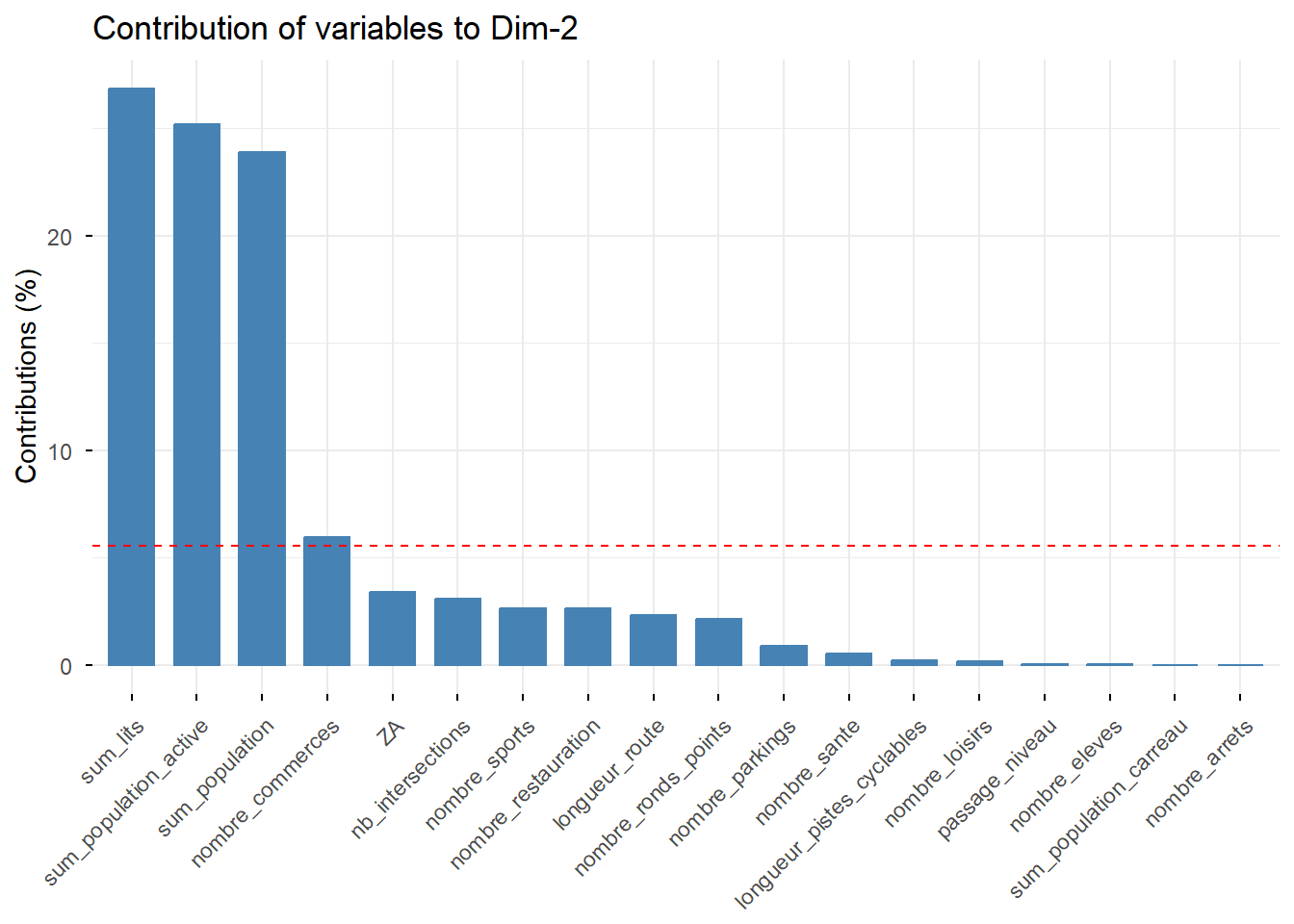
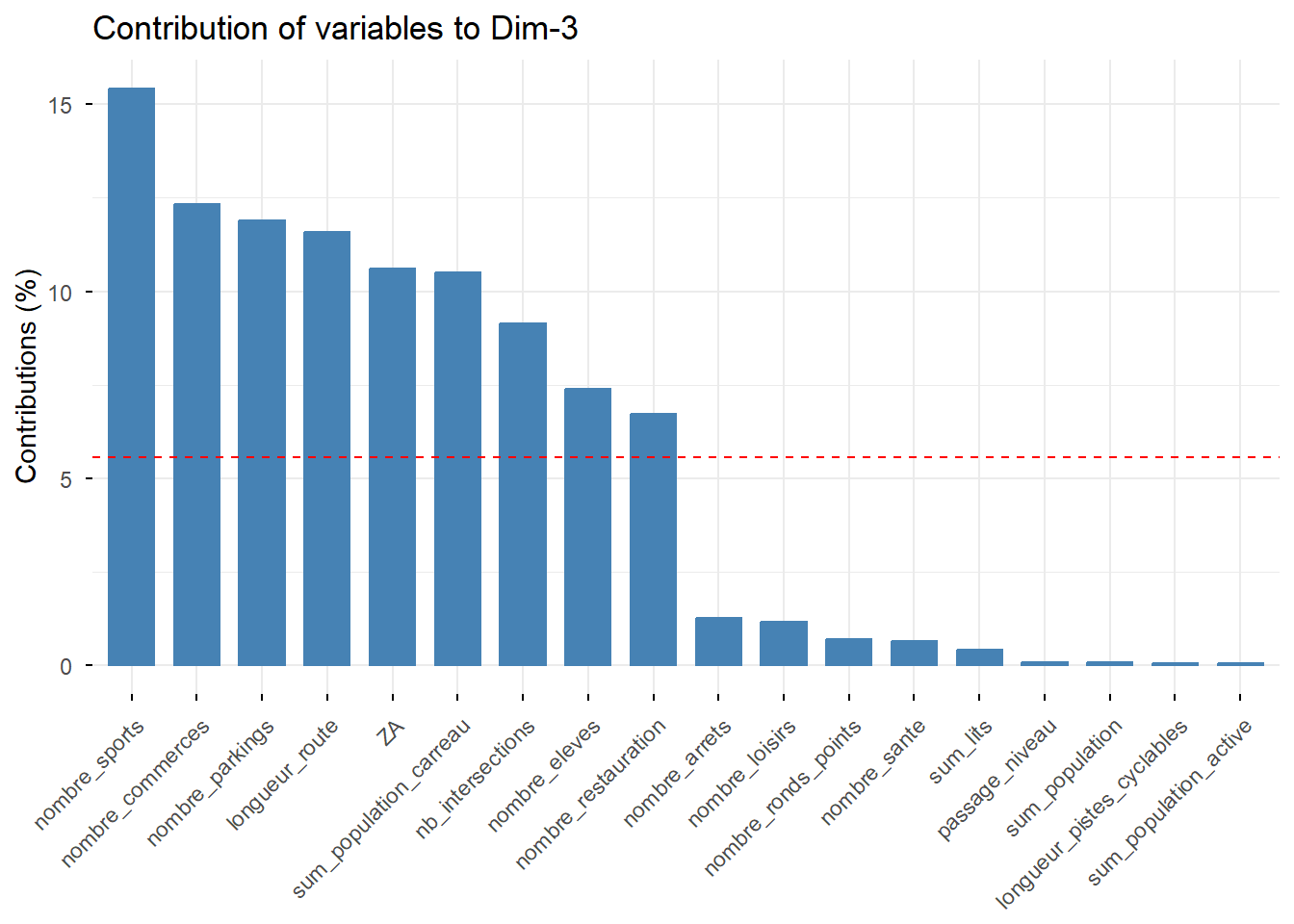
3 - Classification ascendante hiérarchique et cartographie
# CAH sur les scores des individus de l'ACP ----
hc <- HCPC(PCA, nb.clust = 3, graph = FALSE)
# Visualiser les dendrogrammes
fviz_dend(hc, cex = 0.5)## Warning: The `<scale>` argument of `guides()` cannot be `FALSE`. Use "none" instead as
## of ggplot2 3.3.4.
## ℹ The deprecated feature was likely used in the factoextra package.
## Please report the issue at <https://github.com/kassambara/factoextra/issues>.
## This warning is displayed once every 8 hours.
## Call `lifecycle::last_lifecycle_warnings()` to see where this warning was
## generated.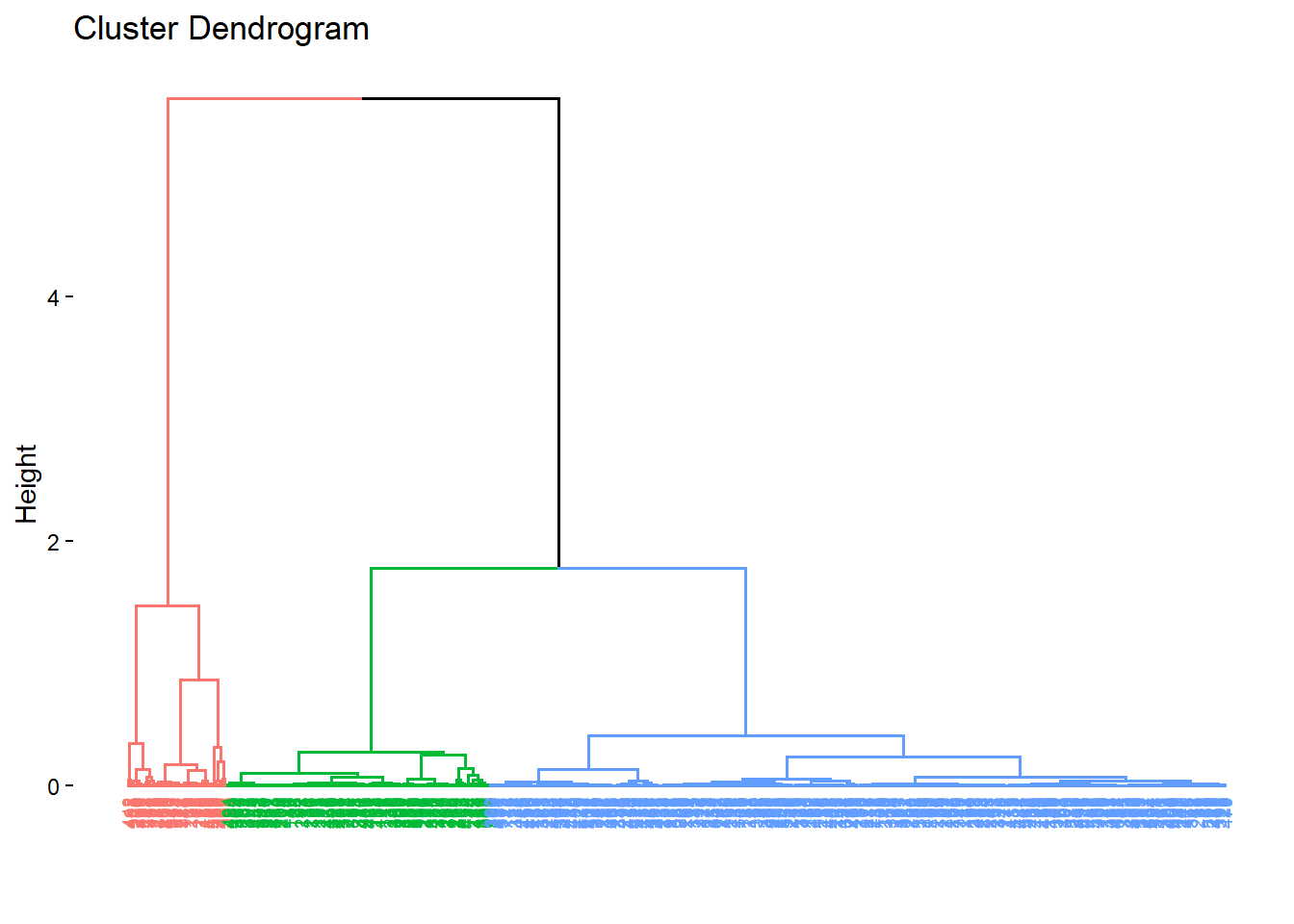
# Visualiser les individus dans le plan factoriel avec une indication de leur cluster
fviz_cluster(hc, geom = "point")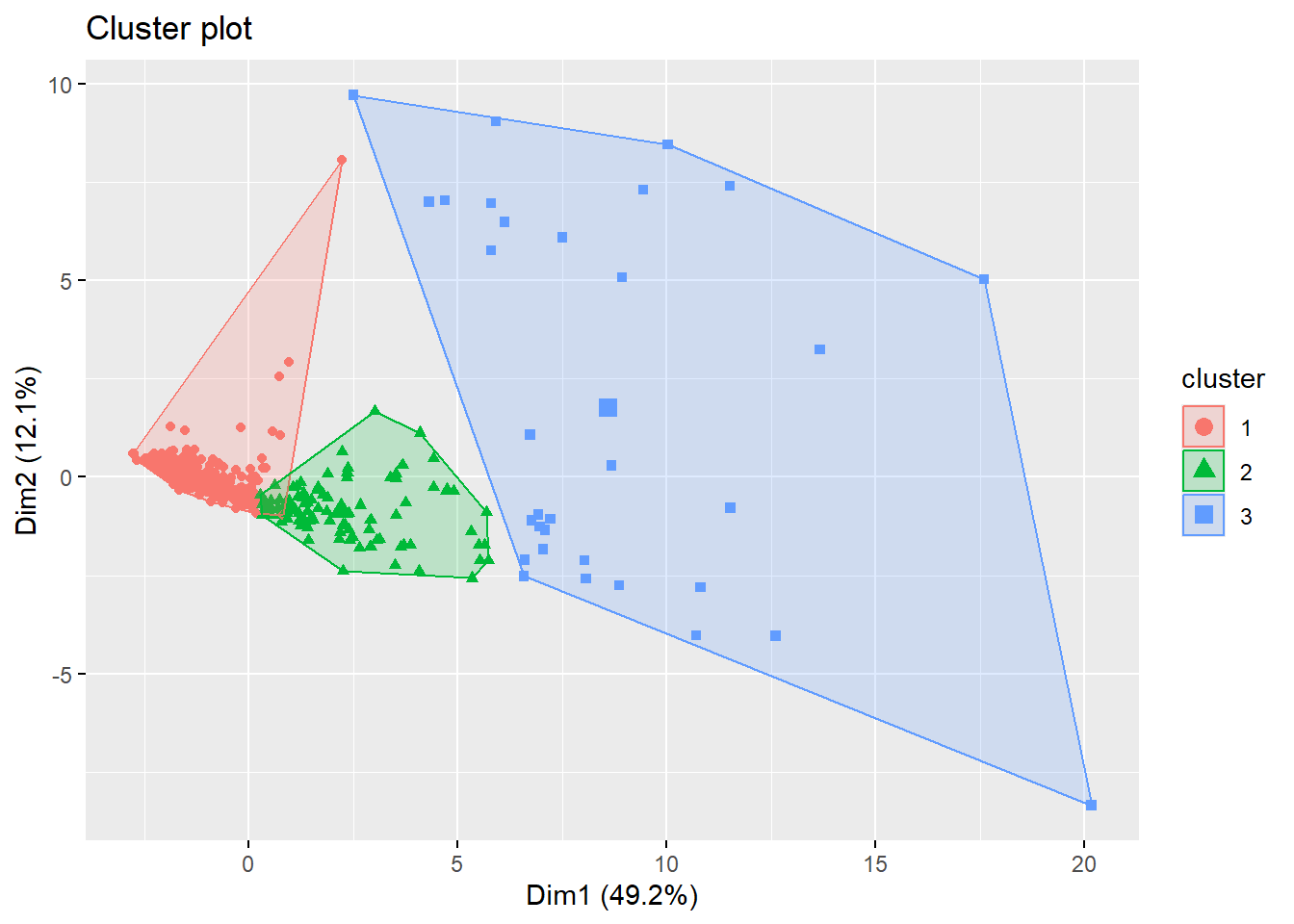
# Extraction des clusters attribués à chaque observation
clusters <- hc$data.clust$clust
length(clusters)## [1] 498## [1] 498## ℹ tmap modes "plot" - "view"
## ℹ toggle with `tmap::ttm()`tm_shape(all_data_filter) +
tm_dots(col = "cluster", palette = "Set1", title = "Cluster") +
tm_basemap(server = "OpenStreetMap") +
tm_layout(legend.position = c("left", "bottom"))##
## ── tmap v3 code detected ───────────────────────────────────────────────────────
## [v3->v4] `tm_tm_dots()`: migrate the argument(s) related to the scale of the
## visual variable `fill` namely 'palette' (rename to 'values') to fill.scale =
## tm_scale(<HERE>).[v3->v4] `tm_dots()`: use 'fill' for the fill color of polygons/symbols
## (instead of 'col'), and 'col' for the outlines (instead of 'border.col').[tm_dots()] Argument `title` unknown.[cols4all] color palettes: use palettes from the R package cols4all. Run
## `cols4all::c4a_gui()` to explore them. The old palette name "Set1" is named
## "brewer.set1"4 - Construction du modèle de régression linéaire
modele <- lm(
log_voy_2022 ~
sum_population+
sum_population_active+
sum_lits+
longueur_route+
nb_intersections+
# reseau_pedestre+
longueur_pistes_cyclables+
nombre_arrets+
nombre_parkings+
nombre_commerces+
nombre_sante+
nombre_loisirs+
nombre_restauration+
nombre_sports+
nombre_ronds_points+
nombre_eleves+
ZA+
passage_niveau+
sum_population_carreau+
PNR_OK,
data = all_data_filter
)
# Affichage du résumé du modèle pour voir les coefficients et la significativité des variables
summary(modele)##
## Call:
## lm(formula = log_voy_2022 ~ sum_population + sum_population_active +
## sum_lits + longueur_route + nb_intersections + longueur_pistes_cyclables +
## nombre_arrets + nombre_parkings + nombre_commerces + nombre_sante +
## nombre_loisirs + nombre_restauration + nombre_sports + nombre_ronds_points +
## nombre_eleves + ZA + passage_niveau + sum_population_carreau +
## PNR_OK, data = all_data_filter)
##
## Residuals:
## Min 1Q Median 3Q Max
## -6.7953 -1.0824 0.2544 1.4071 4.2212
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 9.1128 0.2753 33.100 < 2e-16 ***
## sum_population -33.6971 13.0266 -2.587 0.009982 **
## sum_population_active 34.3243 14.2528 2.408 0.016407 *
## sum_lits -3.0694 2.3288 -1.318 0.188125
## longueur_route 7.6569 3.0980 2.472 0.013801 *
## nb_intersections 2.8346 2.5832 1.097 0.273038
## longueur_pistes_cyclables -1.4785 0.8027 -1.842 0.066086 .
## nombre_arrets 3.3874 1.2065 2.808 0.005194 **
## nombre_parkings 2.9267 1.2152 2.408 0.016397 *
## nombre_commerces -10.5301 3.3302 -3.162 0.001666 **
## nombre_sante 1.7594 1.1896 1.479 0.139812
## nombre_loisirs -2.6050 1.2568 -2.073 0.038729 *
## nombre_restauration 12.4867 3.6410 3.430 0.000657 ***
## nombre_sports 0.6074 1.5054 0.404 0.686760
## nombre_ronds_points 0.1827 0.6419 0.285 0.776063
## nombre_eleves 0.1439 0.7051 0.204 0.838351
## ZA -2.6464 1.1695 -2.263 0.024099 *
## passage_niveau -1.6457 0.5078 -3.241 0.001274 **
## sum_population_carreau -1.6280 1.1014 -1.478 0.140040
## PNR_OK -0.2293 0.2593 -0.885 0.376870
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 1.899 on 478 degrees of freedom
## Multiple R-squared: 0.3877, Adjusted R-squared: 0.3633
## F-statistic: 15.93 on 19 and 478 DF, p-value: < 2.2e-16Coefficient de détermination
## [1] 0.3876705Diagnostic visuel des résidus
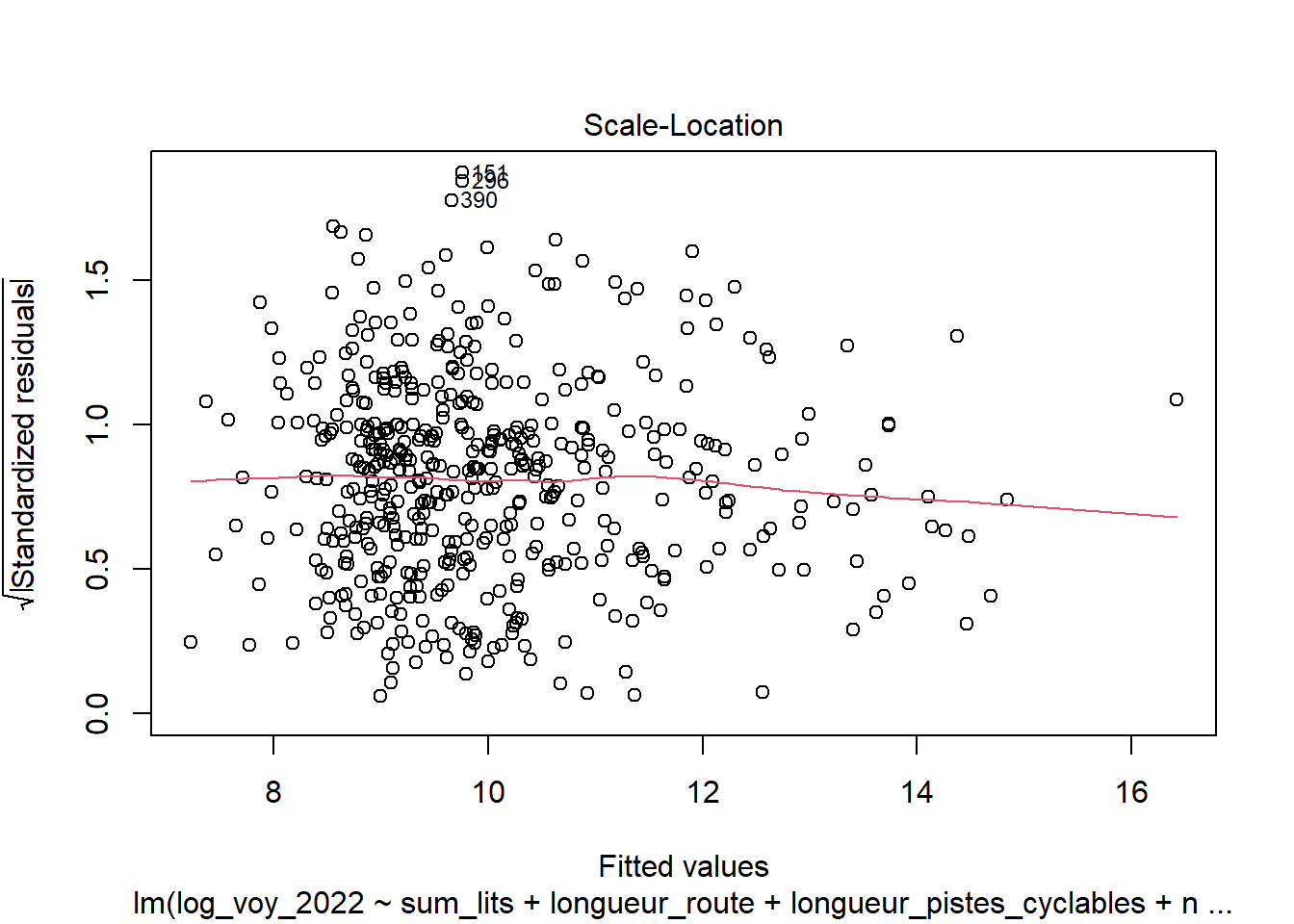
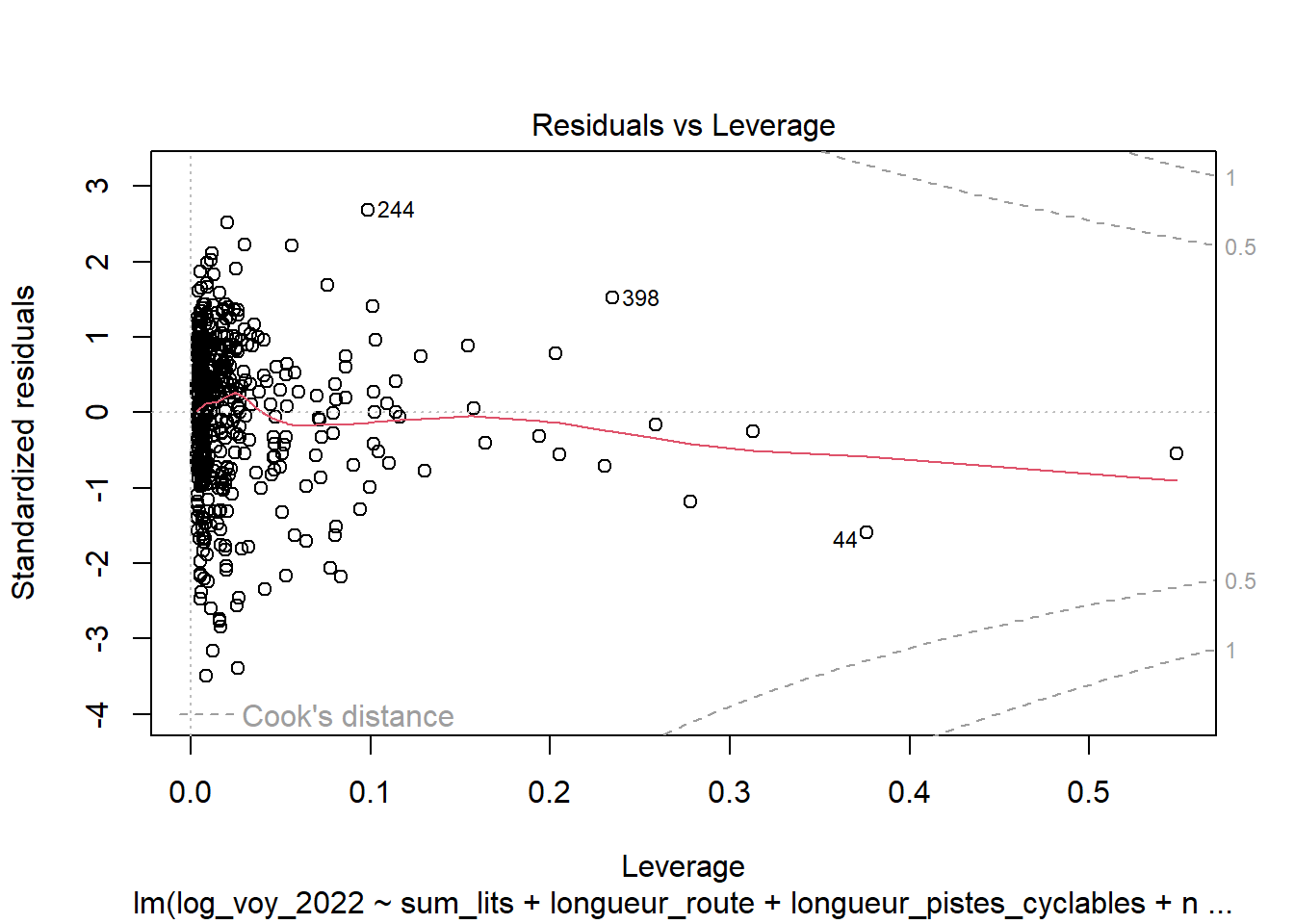
Quatre graphiques de diagnostic résiduels pour aider à évaluer la qualité de l’ajustement du modèle. Ces graphiques fournissent des informations visuelles sur divers aspects des résidus et des ajustements du modèle :
Observation des linéarités des relations : Résidus vs Valeurs Prédites : Ce graphique montre les résidus (différences entre les valeurs observées et les valeurs prédites) en fonction des valeurs prédites par le modèle. L’idéal est de voir une dispersion aléatoire des points autour de la ligne horizontale à zéro, indiquant l’homoscédasticité (variance constante des résidus). Des motifs ou des tendances dans ce graphique peuvent indiquer des problèmes d’hétéroscédasticité ou des non-linéarités non capturées par le modèle.
Normalité des résidus : Q-Q Plot des Résidus Standardisés : Ce graphique compare la distribution des résidus standardisés à une distribution normale théorique. Si les résidus sont normalement distribués, les points devraient approximativement suivre la ligne diagonale. Des écarts significatifs de cette ligne peuvent indiquer une violation de l’hypothèse de normalité des résidus, ce qui peut affecter les tests d’hypothèse et les intervalles de confiance associés au modèle. (Voir aussi test de Shapiro-Wilk)
Homoscédasticité Scale-Location (ou Spread-Location) : Ce graphique montre la racine carrée des valeurs absolues des résidus standardisés en fonction des valeurs prédites. Il est utilisé pour vérifier l’homoscédasticité des résidus. Comme pour le premier graphique, une dispersion aléatoire sans motif clair est l’indicateur d’une bonne homoscédasticité. Des motifs ou des tendances peuvent indiquer des problèmes d’hétéroscédasticité. (Voir aussi test de Breusch-Pagan)
- Résidus vs Leviers (ou Leverage) : Ce graphique montre les résidus standardisés en fonction des leviers (ou valeurs de levier) pour chaque observation. Les points avec un levier élevé ont une influence plus importante sur l’ajustement du modèle. Les observations situées loin de la majorité des données (en termes de valeurs de levier) ou ayant des résidus standardisés importants sont particulièrement intéressantes car elles peuvent être des valeurs aberrantes ou des points influents.
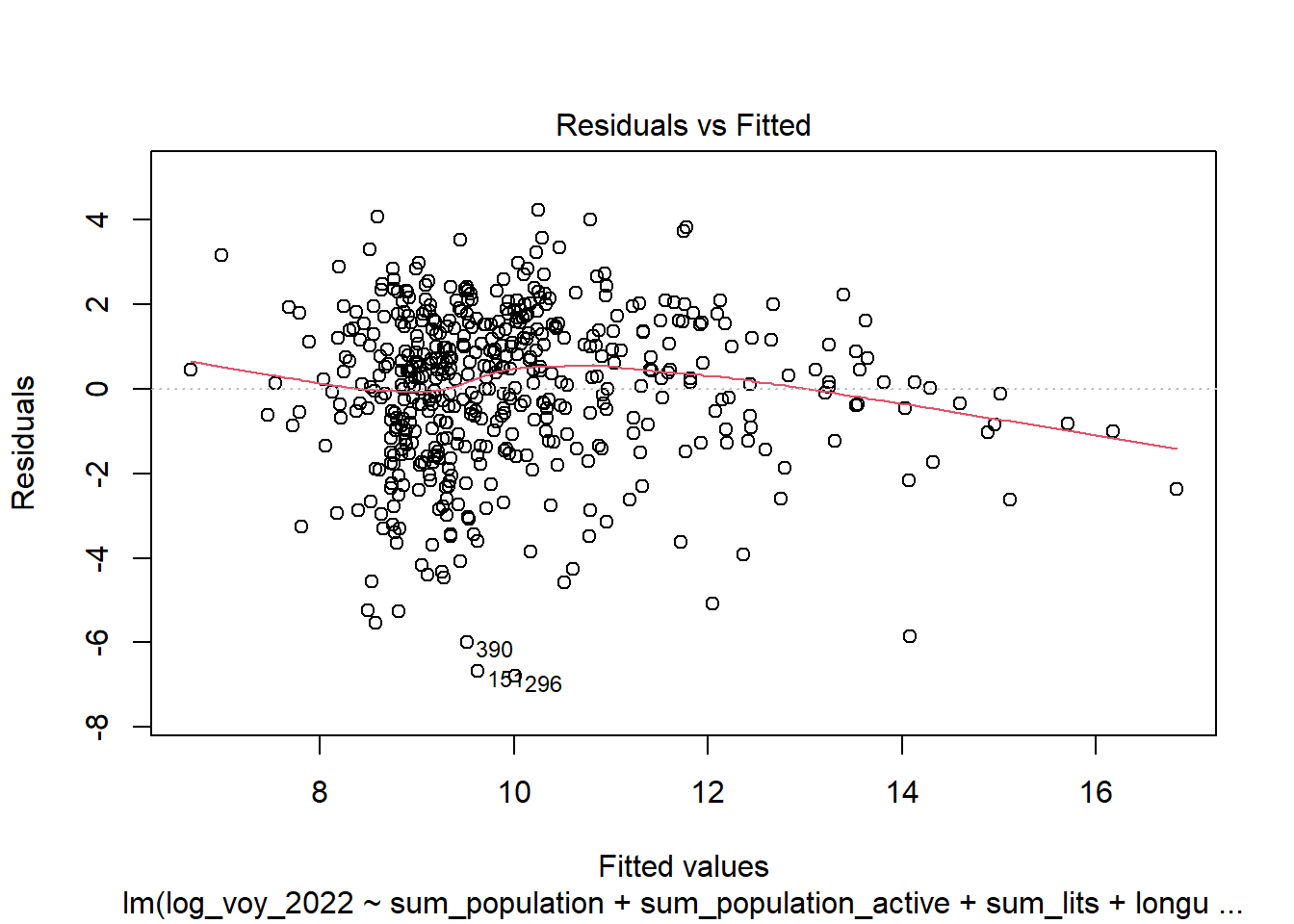
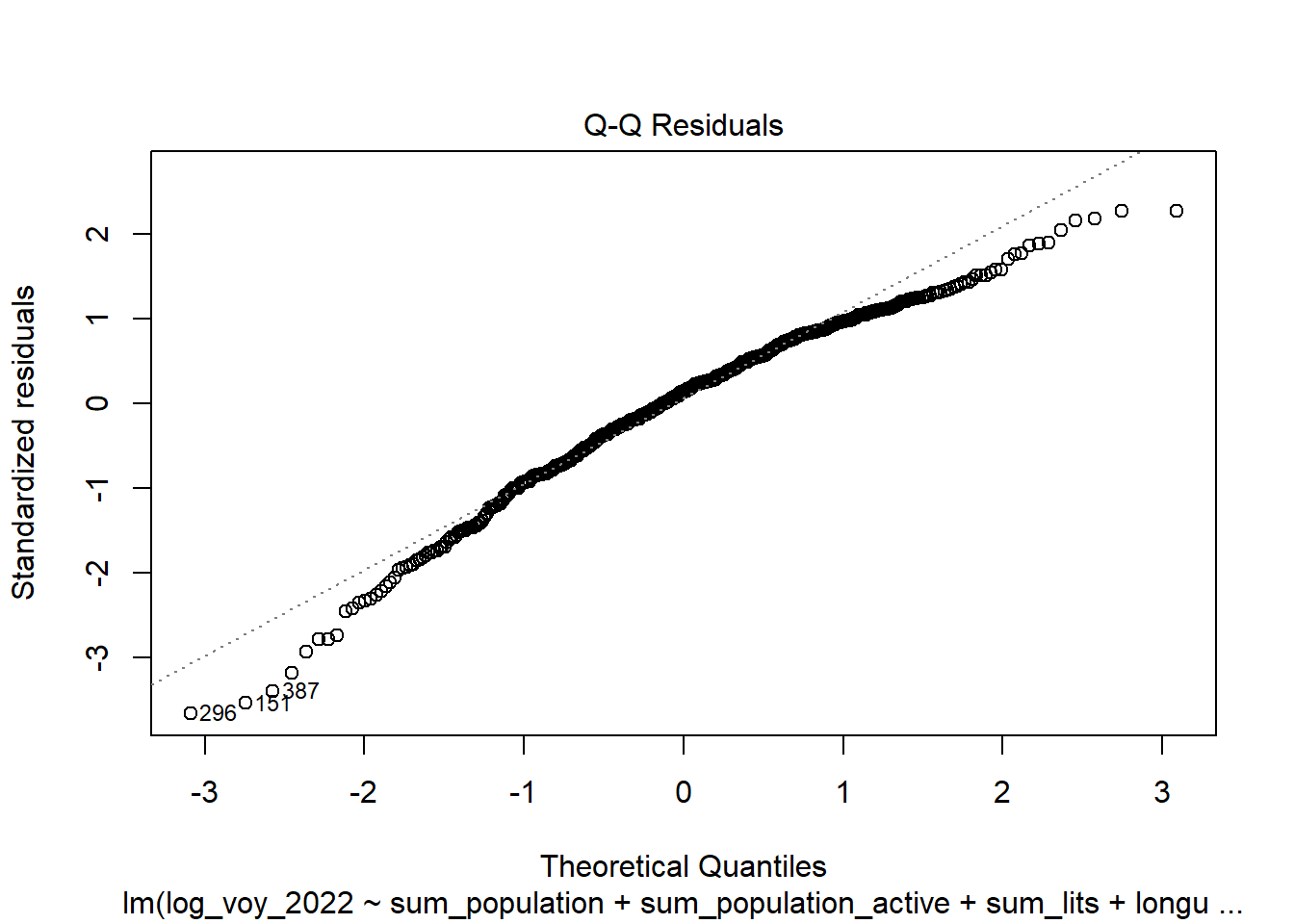
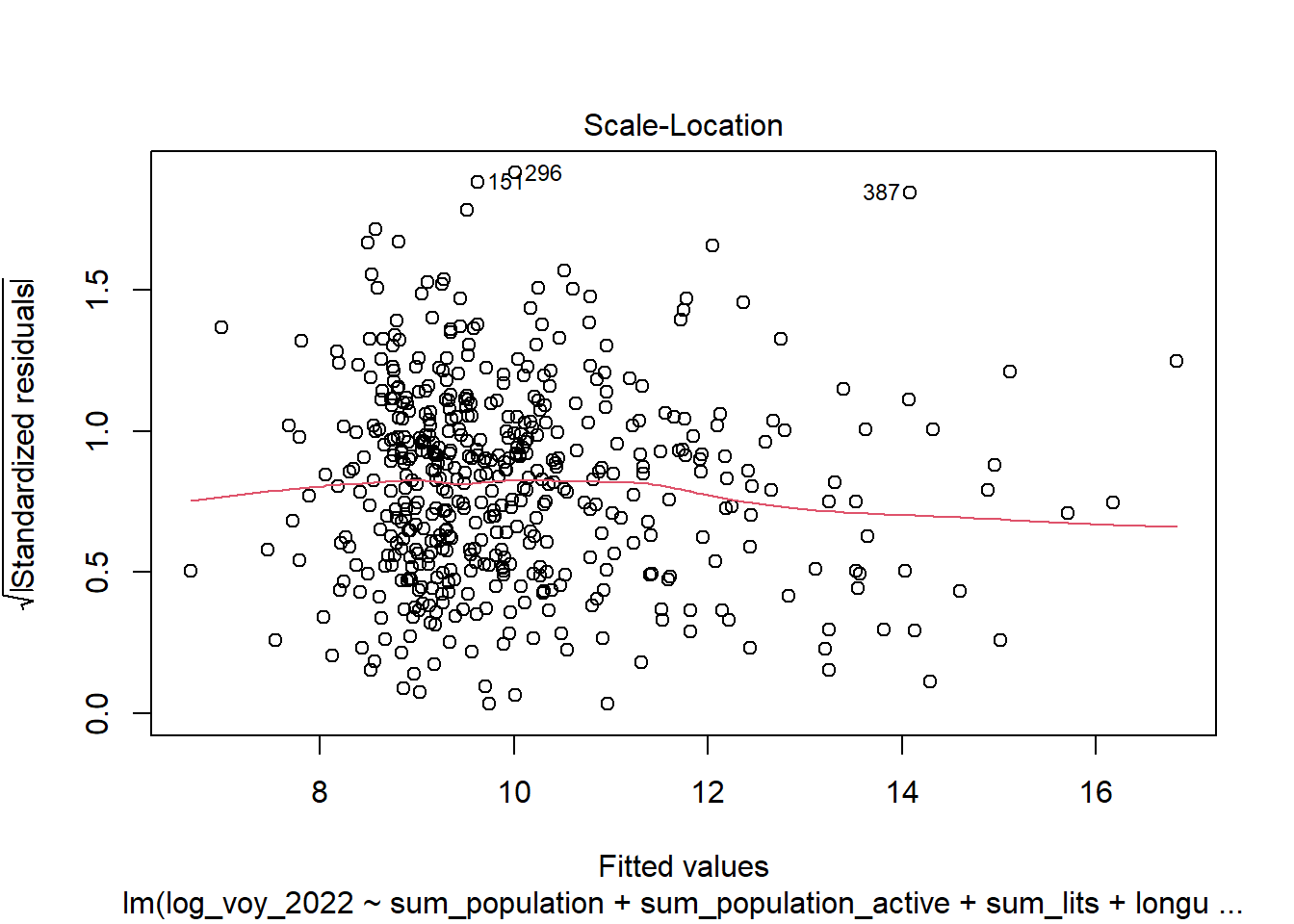
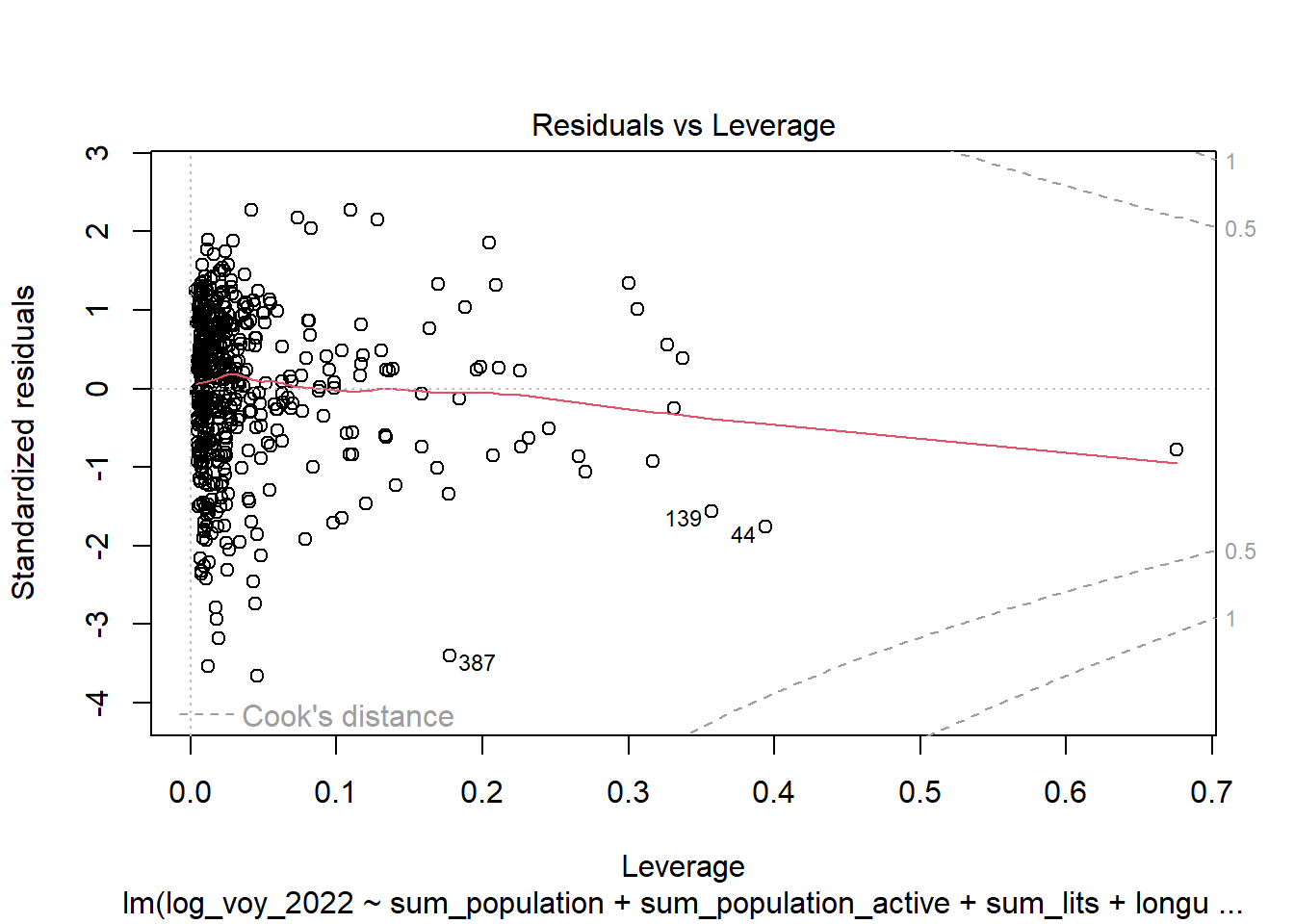
Normalité des résidus
La valeur p est de 3.855e-08, ce qui est inférieur au seuil commun de 0.05. Cela indique que nous avons suffisamment de preuves pour rejeter l’hypothèse nulle de normalité des résidus. En d’autres termes, il y a des preuves statistiques suggérant que les résidus du modèle ne suivent pas une distribution normale.
##
## Shapiro-Wilk normality test
##
## data: residuals(modele)
## W = 0.97209, p-value = 3.855e-08Homoscédasticité des résidus (homogénéité)
Avec une valeur p de 0.29899, ce test ne rejette pas l’hypothèse nulle d’homoscédasticité au seuil de significativité commun de 0.05. Cela suggère que les données ne montrent pas de preuves statistiquement significatives d’hétéroscédasticité selon ce test, et que l’assomption d’homoscédasticité (variance constante des résidus) pour le modèle de régression est raisonnablement satisfaite.
## Non-constant Variance Score Test
## Variance formula: ~ fitted.values
## Chisquare = 1.078696, Df = 1, p = 0.298995 - Multicolinéarité
L’un des points les plus importants en régression multiple est de respecter l’indépendance entre les variables exogènes (absence de colinéarité), le risque étant sinon de biaiser les estimations des erreurs types des coefficients de régression. La VIF (variance inflation factor) est une bonne méthode pour détecter ces problèmes de colinéarité.
Le “Variance Inflation Factor” (VIF) est calculé pour chaque variable explicative d’un modèle de régression. Pour calculer le VIF d’une variable, on réalise une régression de cette variable en fonction de toutes les autres variables explicatives du modèle. Le VIF est ensuite calculé comme étant 1 divisé par (1 - R²) de cette régression, où R² est le coefficient de détermination de la régression. Ainsi, le VIF mesure combien la variance d’un estimateur de régression est gonflée à cause de la multicollinéarité. La fonction vif() du package car permet de la calculer.
| Characteristic | Beta | 95% CI | p-value | VIF |
|---|---|---|---|---|
| sum_population | -34 | -59, -8.1 | 0.010 | 627 |
| sum_population_active | 34 | 6.3, 62 | 0.016 | 729 |
| sum_lits | -3.1 | -7.6, 1.5 | 0.2 | 18 |
| longueur_route | 7.7 | 1.6, 14 | 0.014 | 41 |
| nb_intersections | 2.8 | -2.2, 7.9 | 0.3 | 30 |
| longueur_pistes_cyclables | -1.5 | -3.1, 0.10 | 0.066 | 1.8 |
| nombre_arrets | 3.4 | 1.0, 5.8 | 0.005 | 2.3 |
| nombre_parkings | 2.9 | 0.54, 5.3 | 0.016 | 1.7 |
| nombre_commerces | -11 | -17, -4.0 | 0.002 | 7.8 |
| nombre_sante | 1.8 | -0.58, 4.1 | 0.14 | 3.9 |
| nombre_loisirs | -2.6 | -5.1, -0.14 | 0.039 | 3.8 |
| nombre_restauration | 12 | 5.3, 20 | <0.001 | 9.5 |
| nombre_sports | 0.61 | -2.4, 3.6 | 0.7 | 2.1 |
| nombre_ronds_points | 0.18 | -1.1, 1.4 | 0.8 | 2.0 |
| nombre_eleves | 0.14 | -1.2, 1.5 | 0.8 | 1.5 |
| ZA | -2.6 | -4.9, -0.35 | 0.024 | 5.9 |
| passage_niveau | -1.6 | -2.6, -0.65 | 0.001 | 1.2 |
| sum_population_carreau | -1.6 | -3.8, 0.54 | 0.14 | 6.3 |
| PNR_OK | -0.23 | -0.74, 0.28 | 0.4 | 1.1 |
| Abbreviations: CI = Confidence Interval, VIF = Variance Inflation Factor | ||||
Les valeurs du Facteur d’Inflation de la Variance (VIF) fournissent une indication de la présence de multicolinéarité parmi les variables explicatives dans un modèle de régression linéaire. En règle générale, un VIF supérieur à 5 est souvent considéré comme indiquant une forte multicolinéarité, nécessitant une action pour réduire cette multicollinéarité dans le modèle.
6 - Construction du modèle de régression linéaire avec moins de variable (VIF < 5)
Nous avons procédé de manière itérative en supprimant des variables au fur et à mesure. Finalement nous conservons les valeurs suivantes :
- sum_lits
- longueur_route
- longueur_pistes_cyclables
- nombre_arrets
- nombre_parkings
- nombre_commerces
- nombre_sports
- nombre_ronds_points
- nombre_eleves
- passage_niveau
- sum_population_carreau
- PNR_OK
- pente (pour le vélo)
modele <- lm(
log_voy_2022 ~
# sum_population+
# sum_population_active+
sum_lits+
longueur_route+
# nb_intersections+
# reseau_pedestre+
longueur_pistes_cyclables+
nombre_arrets+
nombre_parkings+
nombre_commerces+
# nombre_sante+
# nombre_loisirs+
# nombre_restauration+
nombre_sports+
nombre_ronds_points+
nombre_eleves+
# ZA+
passage_niveau+
sum_population_carreau+
PNR_OK,
data = all_data_filter
)Affichage du résumé du modèle pour voir les coefficients et la significativité des variables
##
## Call:
## lm(formula = log_voy_2022 ~ sum_lits + longueur_route + longueur_pistes_cyclables +
## nombre_arrets + nombre_parkings + nombre_commerces + nombre_sports +
## nombre_ronds_points + nombre_eleves + passage_niveau + sum_population_carreau +
## PNR_OK, data = all_data_filter)
##
## Residuals:
## Min 1Q Median 3Q Max
## -6.8108 -1.2167 0.1972 1.4069 4.9833
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 8.5266 0.2009 42.440 < 2e-16 ***
## sum_lits -1.9555 0.6921 -2.826 0.00491 **
## longueur_route 6.9574 1.1020 6.313 6.17e-10 ***
## longueur_pistes_cyclables -0.6509 0.8035 -0.810 0.41830
## nombre_arrets 2.4199 1.1462 2.111 0.03527 *
## nombre_parkings 2.9557 1.2282 2.406 0.01648 *
## nombre_commerces -1.6165 1.8779 -0.861 0.38979
## nombre_sports 0.9617 1.5137 0.635 0.52551
## nombre_ronds_points 0.3131 0.6267 0.500 0.61764
## nombre_eleves 0.6110 0.6973 0.876 0.38135
## passage_niveau -2.0668 0.4977 -4.153 3.88e-05 ***
## sum_population_carreau -0.7852 0.9468 -0.829 0.40734
## PNR_OK -0.1757 0.2609 -0.674 0.50086
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 1.955 on 485 degrees of freedom
## Multiple R-squared: 0.3415, Adjusted R-squared: 0.3252
## F-statistic: 20.96 on 12 and 485 DF, p-value: < 2.2e-16Un modèle de régression linéaire multiple permet de faire trois choses principales avec les variables d’une étude :
Trouver des Coefficients : le modèle donne un coefficient (un nombre) pour chaque variable indépendante examinée. Ce coefficient nous dit comment, et de combien, on peut s’attendre à ce que la variable dépendante change quand la variable indépendante change d’une unité, en gardant toutes les autres variables constantes.
Juger de leur Force : La taille ou la valeur absolue de chaque coefficient nous donne une idée de la force de l’effet de cette variable indépendante sur la variable dépendante. Un grand coefficient (en valeur absolue) signifie un grand effet : si la variable indépendante augmente d’un peu, la variable dépendante change de beaucoup.
Évaluer leur Significativité : Le modèle nous donne aussi une valeur p pour chaque coefficient, qui nous dit si l’effet observé est statistiquement significatif. Une valeur p faible (souvent moins de 0,05) suggère que l’effet n’est probablement pas dû au hasard, et que la variable indépendante a vraiment un impact sur la variable dépendante.
En somme, la régression linéaire multiple est un outil utile pour comprendre et quantifier les relations entre une variable dépendante et plusieurs variables indépendantes, en nous permettant de voir non seulement quels facteurs sont importants, mais aussi comment ils sont importants.
- valeur t comme à un score de force ou de clarté de
l’observation
- valeur p comme à un indicateur de l’importance ou de la
significativité del’observation
- Normalement, une valeur t élevée indique une différence marquée entre le groupe observé et le groupe de référence, ce qui conduit généralement à une valeur p faible, suggérant que les résultats sont statistiquement significatifs.
Coefficient de détermination
## [1] 0.3414632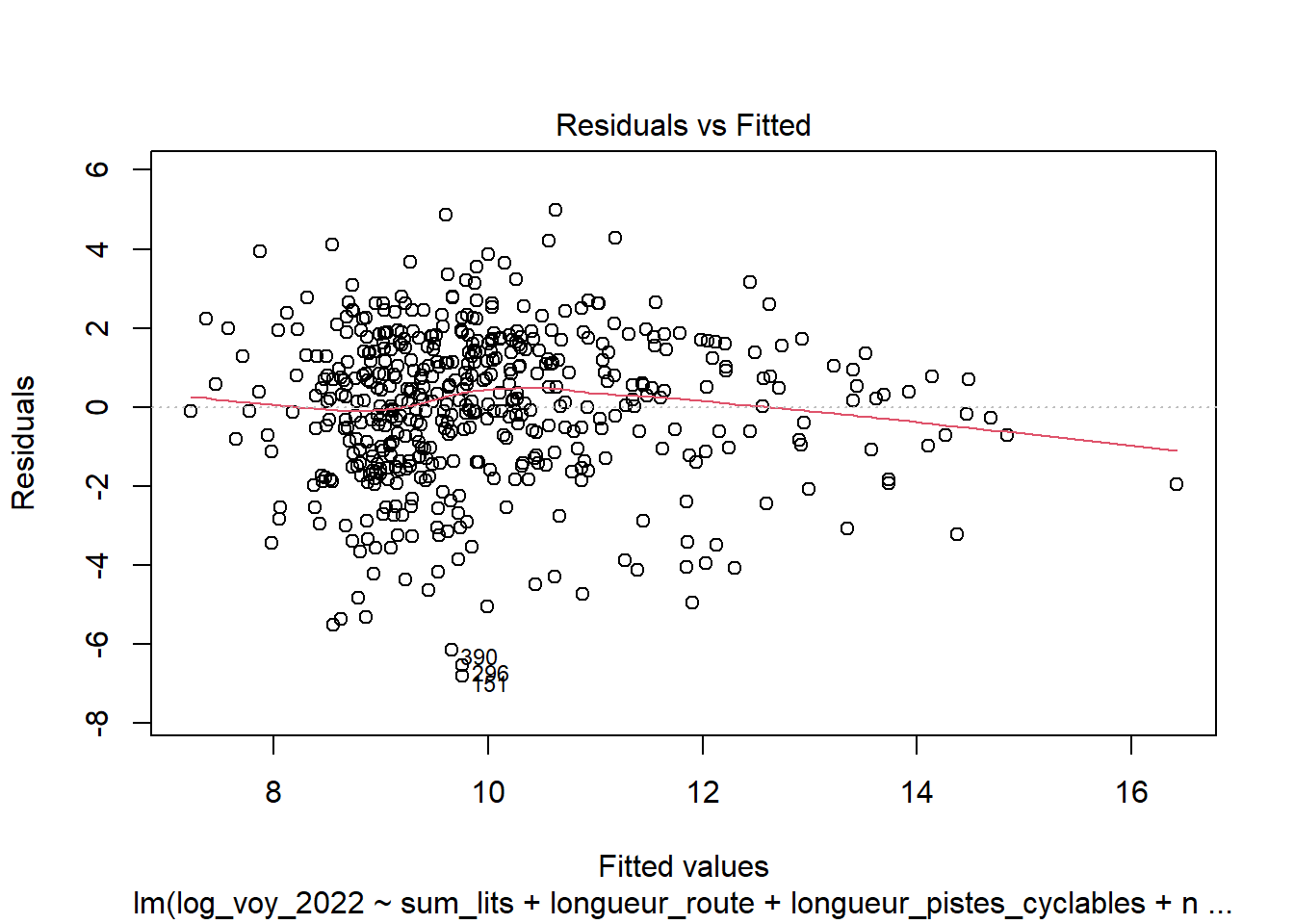
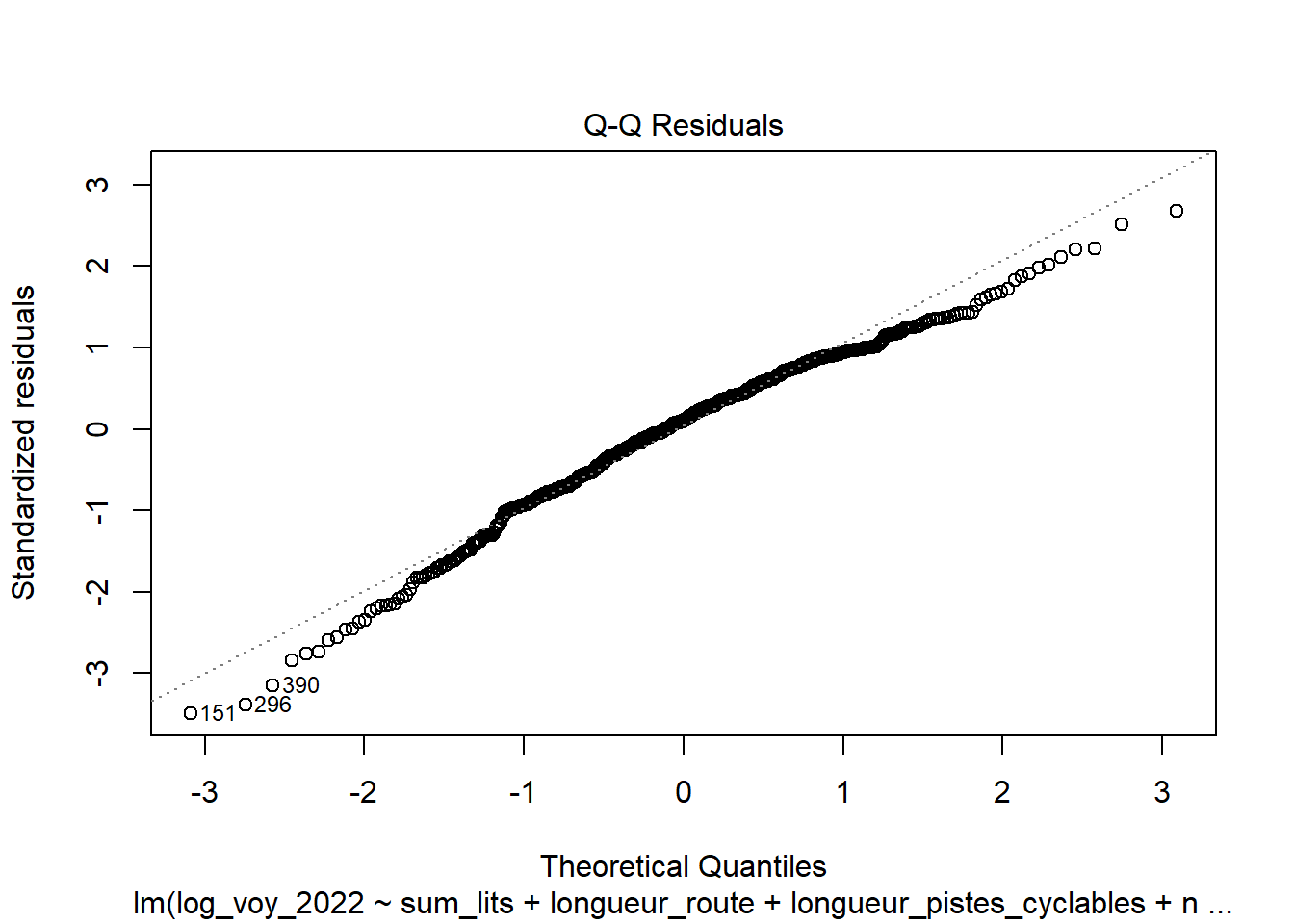
##
## Shapiro-Wilk normality test
##
## data: residuals(modele)
## W = 0.97883, p-value = 1.24e-06## Non-constant Variance Score Test
## Variance formula: ~ fitted.values
## Chisquare = 0.9095079, Df = 1, p = 0.34025# Avec le package gtsummary :
gtsummary::tbl_regression(modele) %>%
gtsummary::add_vif()%>%
gtsummary::as_gt() %>%
gt::tab_footnote(
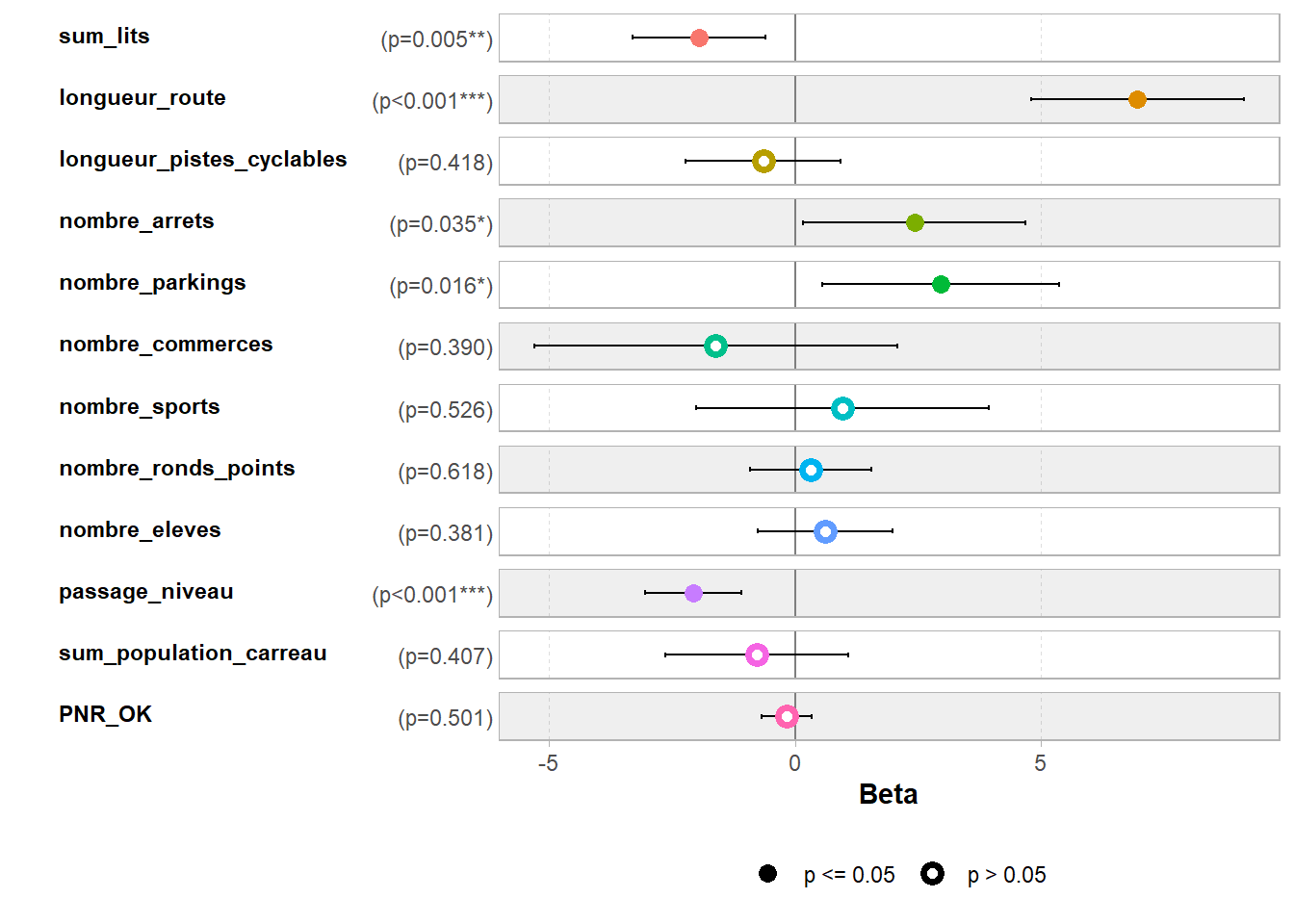
footnote = "Données Hauts-de-France")| Characteristic | Beta | 95% CI | p-value | VIF |
|---|---|---|---|---|
| sum_lits | -2.0 | -3.3, -0.60 | 0.005 | 1.5 |
| longueur_route | 7.0 | 4.8, 9.1 | <0.001 | 4.9 |
| longueur_pistes_cyclables | -0.65 | -2.2, 0.93 | 0.4 | 1.7 |
| nombre_arrets | 2.4 | 0.17, 4.7 | 0.035 | 1.9 |
| nombre_parkings | 3.0 | 0.54, 5.4 | 0.016 | 1.6 |
| nombre_commerces | -1.6 | -5.3, 2.1 | 0.4 | 2.3 |
| nombre_sports | 0.96 | -2.0, 3.9 | 0.5 | 2.0 |
| nombre_ronds_points | 0.31 | -0.92, 1.5 | 0.6 | 1.8 |
| nombre_eleves | 0.61 | -0.76, 2.0 | 0.4 | 1.4 |
| passage_niveau | -2.1 | -3.0, -1.1 | <0.001 | 1.1 |
| sum_population_carreau | -0.79 | -2.6, 1.1 | 0.4 | 4.4 |
| PNR_OK | -0.18 | -0.69, 0.34 | 0.5 | 1.0 |
| Abbreviations: CI = Confidence Interval, VIF = Variance Inflation Factor | ||||
| Données Hauts-de-France | ||||
library(ggplot2)
ggplot(data = all_data_filter, aes(x = longueur_route, y = log_voy_2022)) +
geom_point() +
theme_minimal() +
labs(x = "longueur_route", y = "Nombre de voyageurs", title = "Relation entre la longueur_route et le nombre de voyageurs")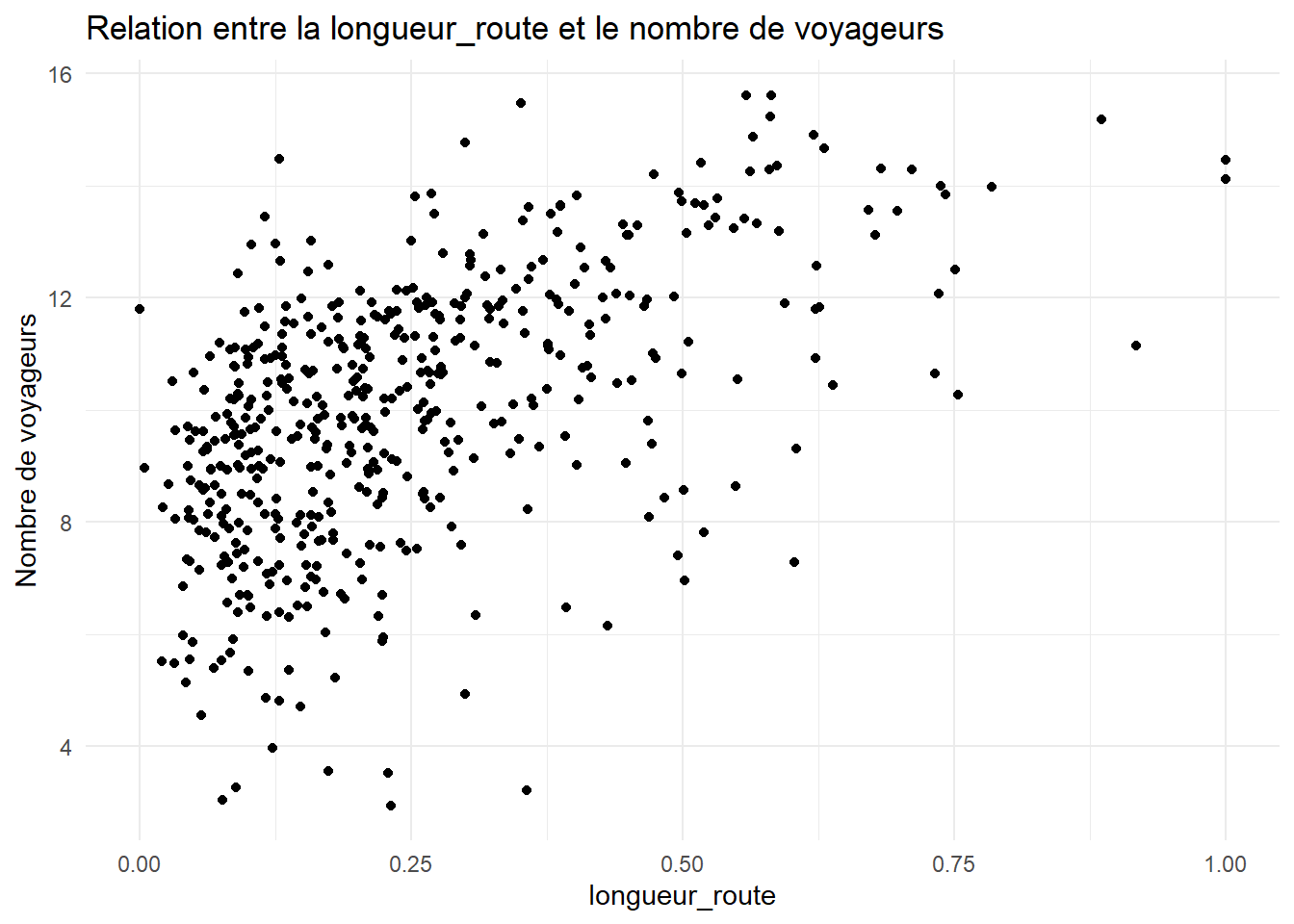
ggplot(data = all_data_filter, aes(x = nombre_arrets, y = log_voy_2022)) +
geom_point() +
theme_minimal() +
labs(x = "nombre_arrets", y = "Nombre de voyageurs", title = "Relation entre nombre_arrets et le nombre de voyageurs")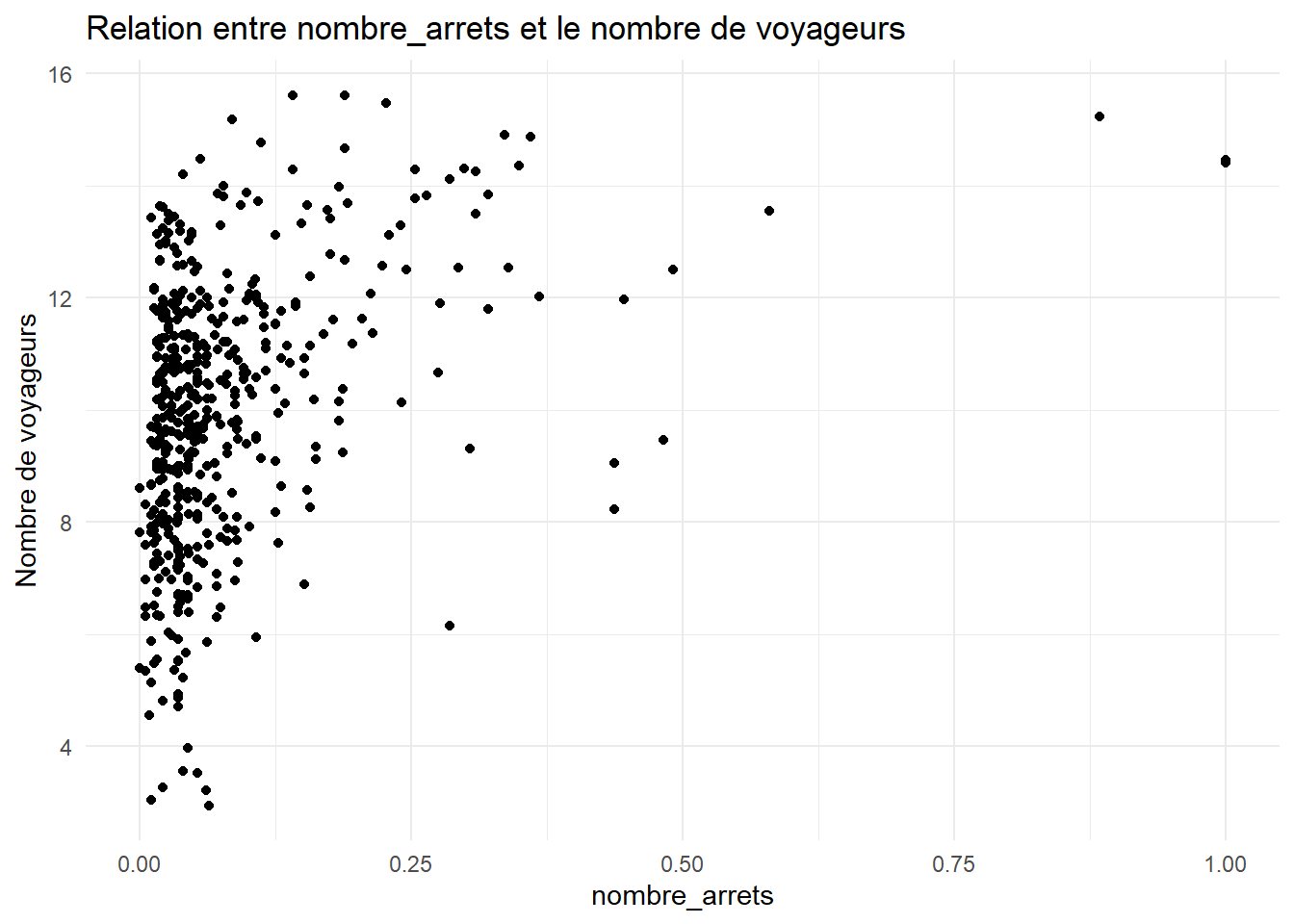
ggplot(data = all_data_filter, aes(x = nombre_parkings, y = log_voy_2022)) +
geom_point() +
theme_minimal() +
labs(x = "nombre_parkings", y = "Nombre de voyageurs", title = "Relation entre nombre_parkings et le nombre de voyageurs")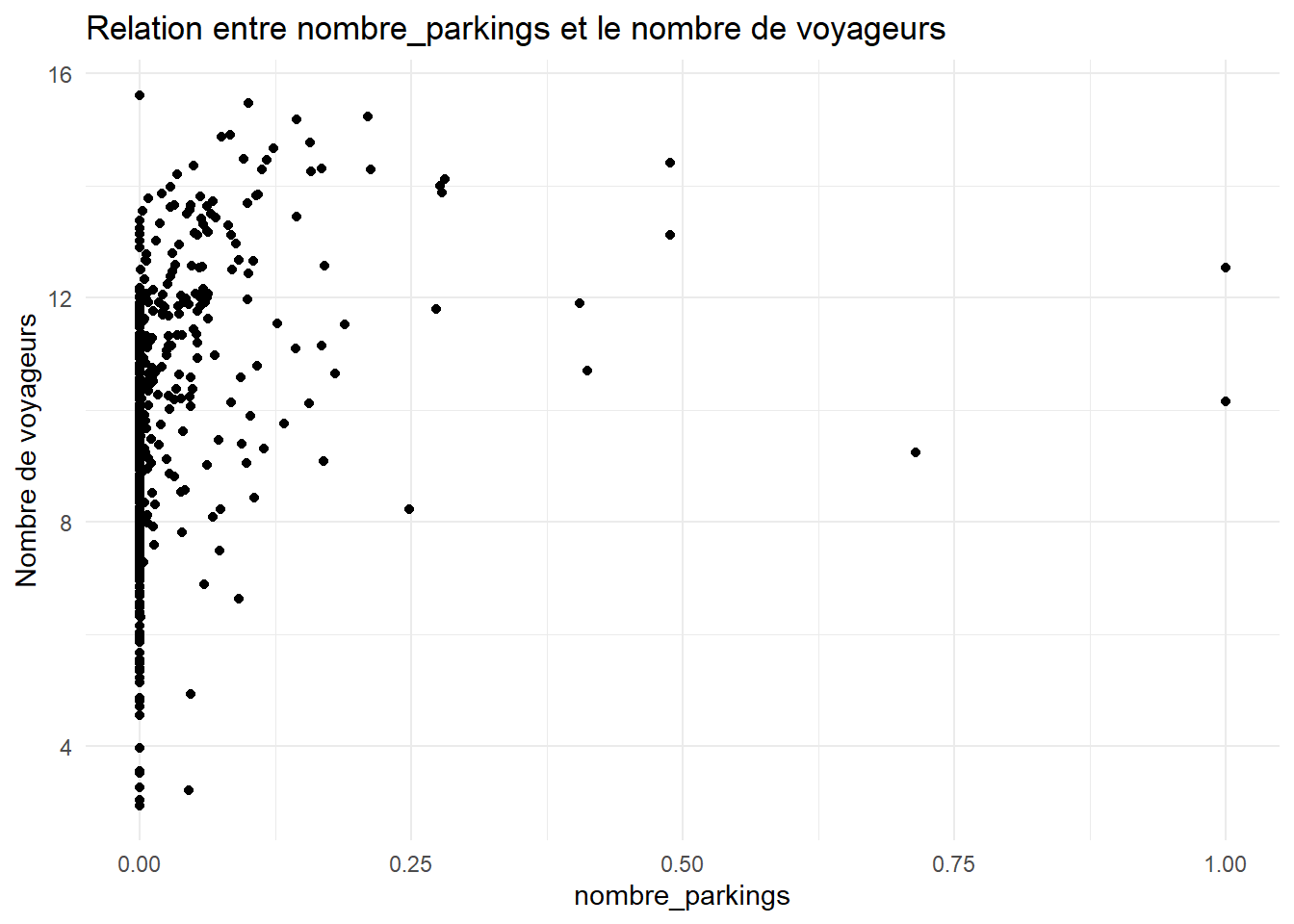
ggplot(data = all_data_filter, aes(x = sum_lits, y = log_voy_2022)) +
geom_point() +
theme_minimal() +
labs(x = "sum_lits", y = "Nombre de voyageurs", title = "Relation entre la sum_lits et le nombre de voyageurs")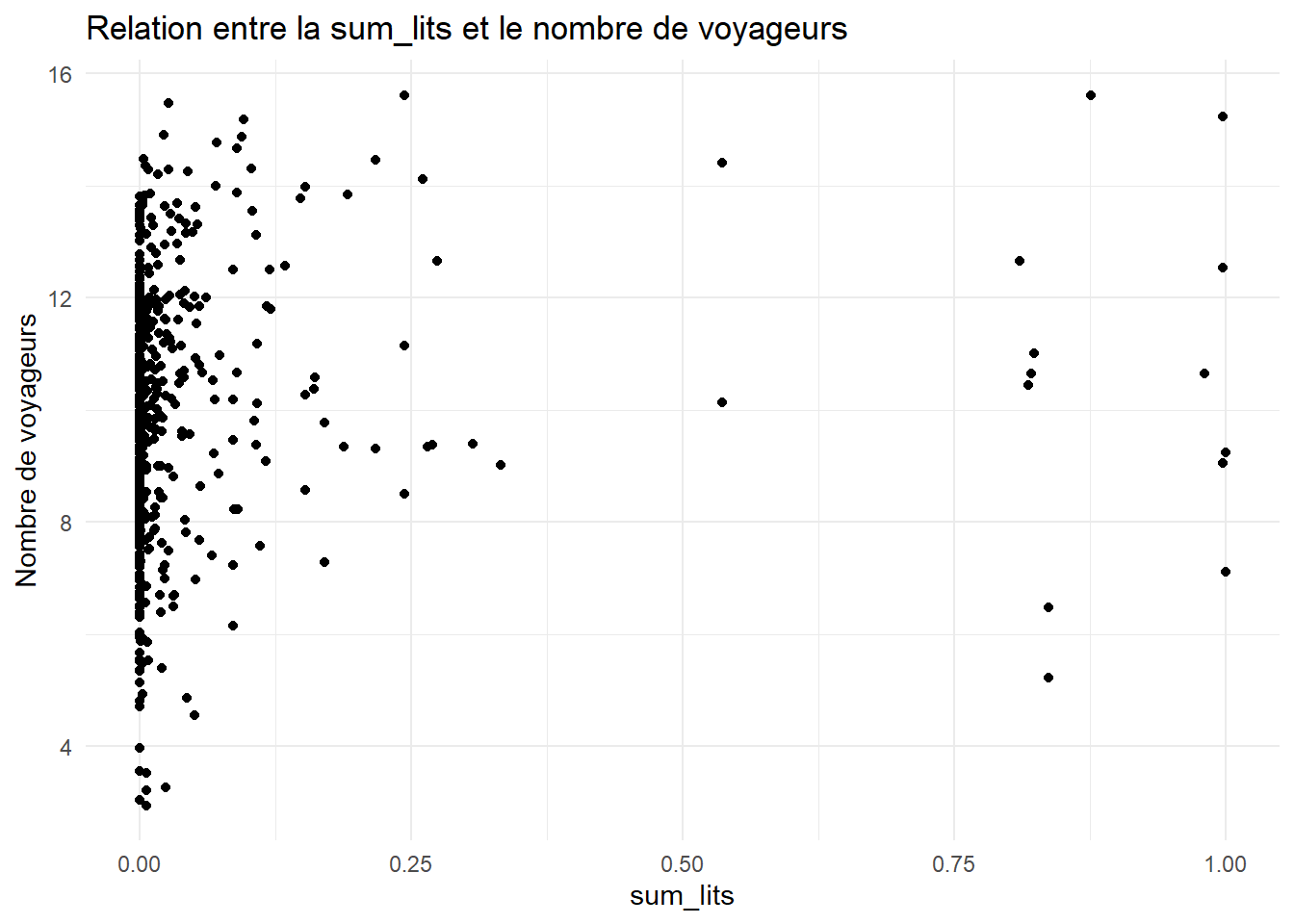
ggplot(data = all_data_filter, aes(x = passage_niveau, y = log_voy_2022)) +
geom_point() +
theme_minimal() +
labs(x = "passage_niveau", y = "Nombre de voyageurs", title = "Relation entre passage_niveau et le nombre de voyageurs")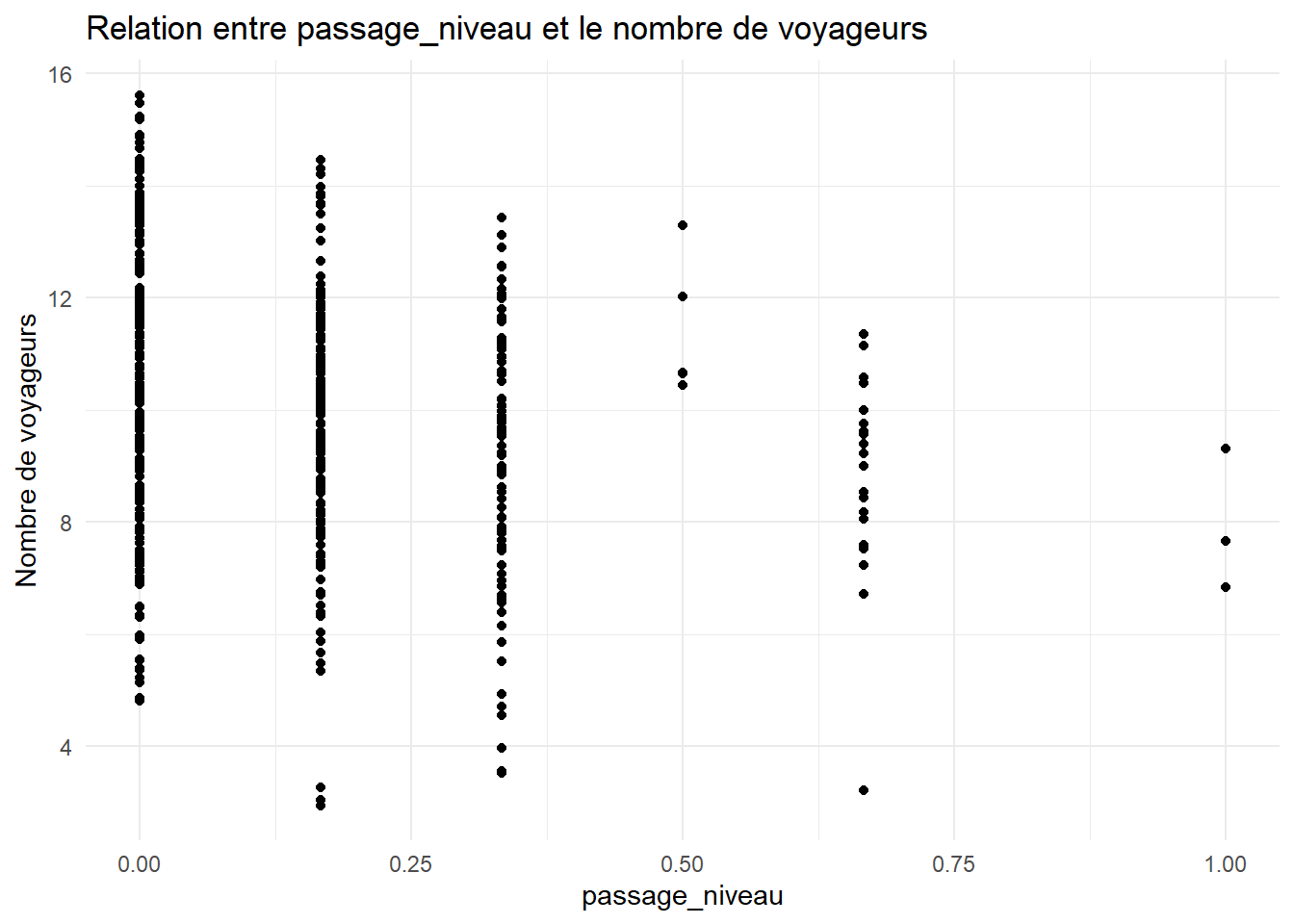
7 - Analyse en composantes principales (ACP)
## Rows: 498
## Columns: 24
## $ ID_number <chr> "Pont de la Deûle", "Les Bons-Pères", "Maube…
## $ voy_2022 <dbl> 24168, 554, 513226, 1989, 238, 3920113, 1494…
## $ sum_population <dbl> 0.1751477517, 0.0189921255, 0.1192634891, 0.…
## $ sum_population_active <dbl> 0.1507132358, 0.0174699951, 0.0942287243, 0.…
## $ sum_lits <dbl> 0.0329117367, 0.0000000000, 0.0425676595, 0.…
## $ longueur_route <dbl> 0.34396799, 0.21975495, 0.50399247, 0.296212…
## $ nb_intersections <dbl> 0.27310924, 0.22899160, 0.51995798, 0.279411…
## $ longueur_pistes_cyclables <dbl> 0.036460243, 0.057294562, 0.080591151, 0.000…
## $ nombre_arrets <dbl> 0.088000000, 0.005333333, 0.026666667, 0.064…
## $ nombre_parkings <dbl> 0.0001071123, 0.0000000000, 0.0502356470, 0.…
## $ nombre_commerces <dbl> 0.004201681, 0.000000000, 0.031512605, 0.008…
## $ nombre_sante <dbl> 0.106796117, 0.000000000, 0.019417476, 0.019…
## $ nombre_loisirs <dbl> 0.01176471, 0.00000000, 0.02352941, 0.047058…
## $ nombre_restauration <dbl> 0.007984032, 0.001996008, 0.059880240, 0.005…
## $ nombre_sports <dbl> 0.00000000, 0.00000000, 0.09090909, 0.000000…
## $ nombre_ronds_points <dbl> 0.2, 0.2, 0.6, 0.3, 0.0, 0.2, 0.0, 0.0, 0.2,…
## $ nombre_eleves <dbl> 0.0000000, 0.0000000, 0.0000000, 0.1255887, …
## $ ZA <dbl> 0.3966329, 0.3235975, 0.4251031, 0.5001756, …
## $ passage_niveau <dbl> 0.1666667, 0.0000000, 0.0000000, 0.6666667, …
## $ sum_population_carreau <dbl> 0.2364492977, 0.0875346748, 0.1503236317, 0.…
## $ PNR_OK <dbl> 0, 1, 0, 1, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0,…
## $ geom <POINT [m]> POINT (706054.2 7033395), POINT (77214…
## $ log_voy_2022 <dbl> 10.092785, 6.317165, 13.148472, 7.595387, 5.…
## $ cluster <fct> 1, 1, 2, 1, 1, 3, 1, 1, 1, 3, 1, 1, 1, 1, 1,…data_select <- all_data_filter %>%
select(# sum_population+
# sum_population_active+
sum_lits,
longueur_route,
# nb_intersections+
# reseau_pedestre+
longueur_pistes_cyclables,
nombre_arrets,
nombre_parkings,
nombre_commerces,
# nombre_sante+
# nombre_loisirs+
# nombre_restauration+
nombre_sports,
nombre_ronds_points,
nombre_eleves,
# ZA+
passage_niveau,
sum_population_carreau,
PNR_OK
) %>%
sf::st_drop_geometry()# Coefficient de corrélation de PEARSON
# Ces coefficients mesurent la force et la direction de la relation linéaire entre chaque paire de variables
stats::cor(data_select, use = "complete.obs")# Lancement de l'ACP
PCA <- FactoMineR::PCA(data_select,
quanti.sup = c(),
quali.sup = c("PNR_OK"), # valeur binaire traitée comme une variable supplémentaire
scale.unit = T) # normalisation des variables## Warning in geom_bar(stat = "identity", fill = barfill, color = barcolor, :
## Ignoring empty aesthetic: `width`.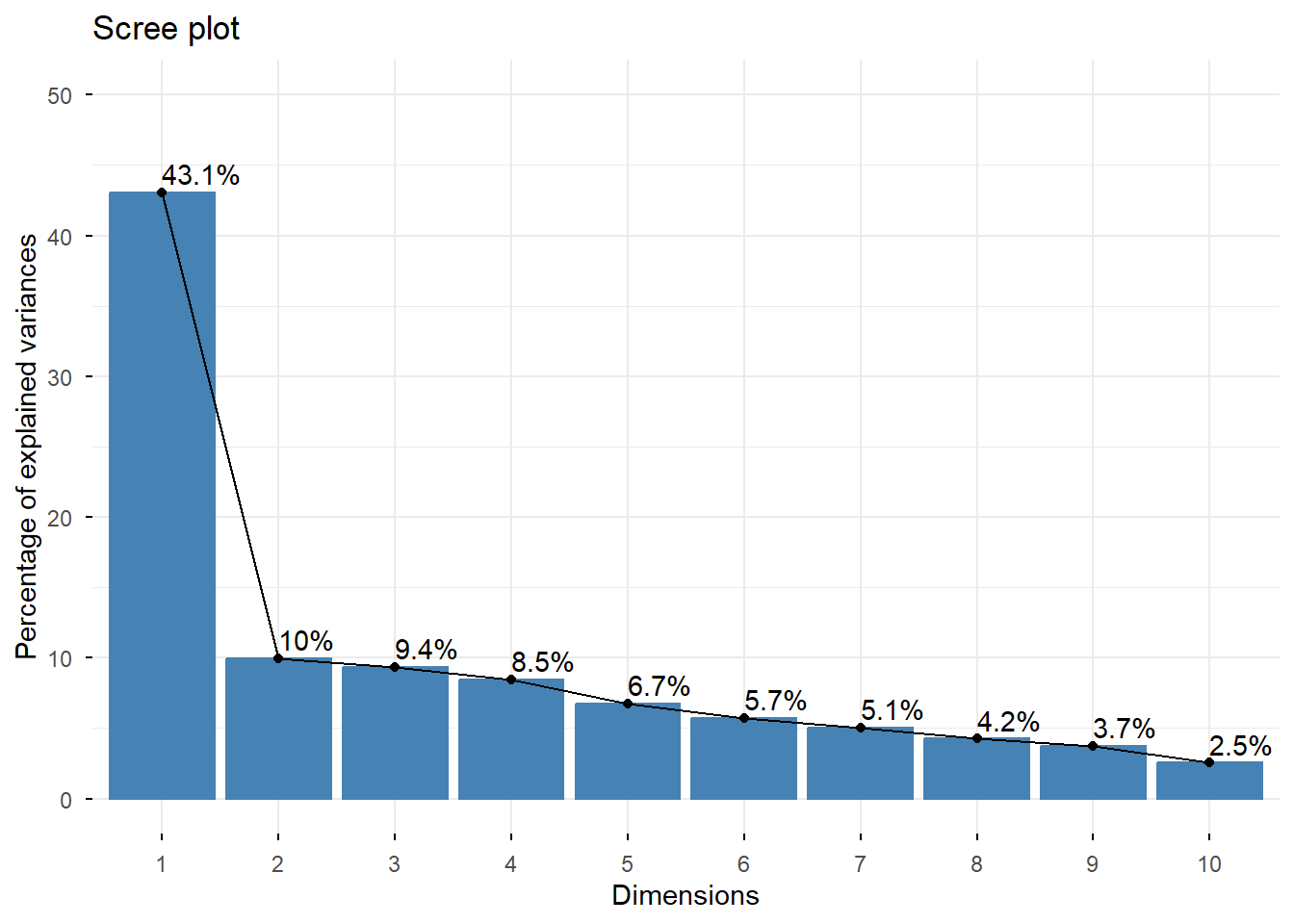
# Cercle des corrélations
factoextra::fviz_pca_var(PCA, col.var="contrib",
gradient.cols = c("#00AFBB", "#E7B800", "#FC4E07"),
repel = TRUE)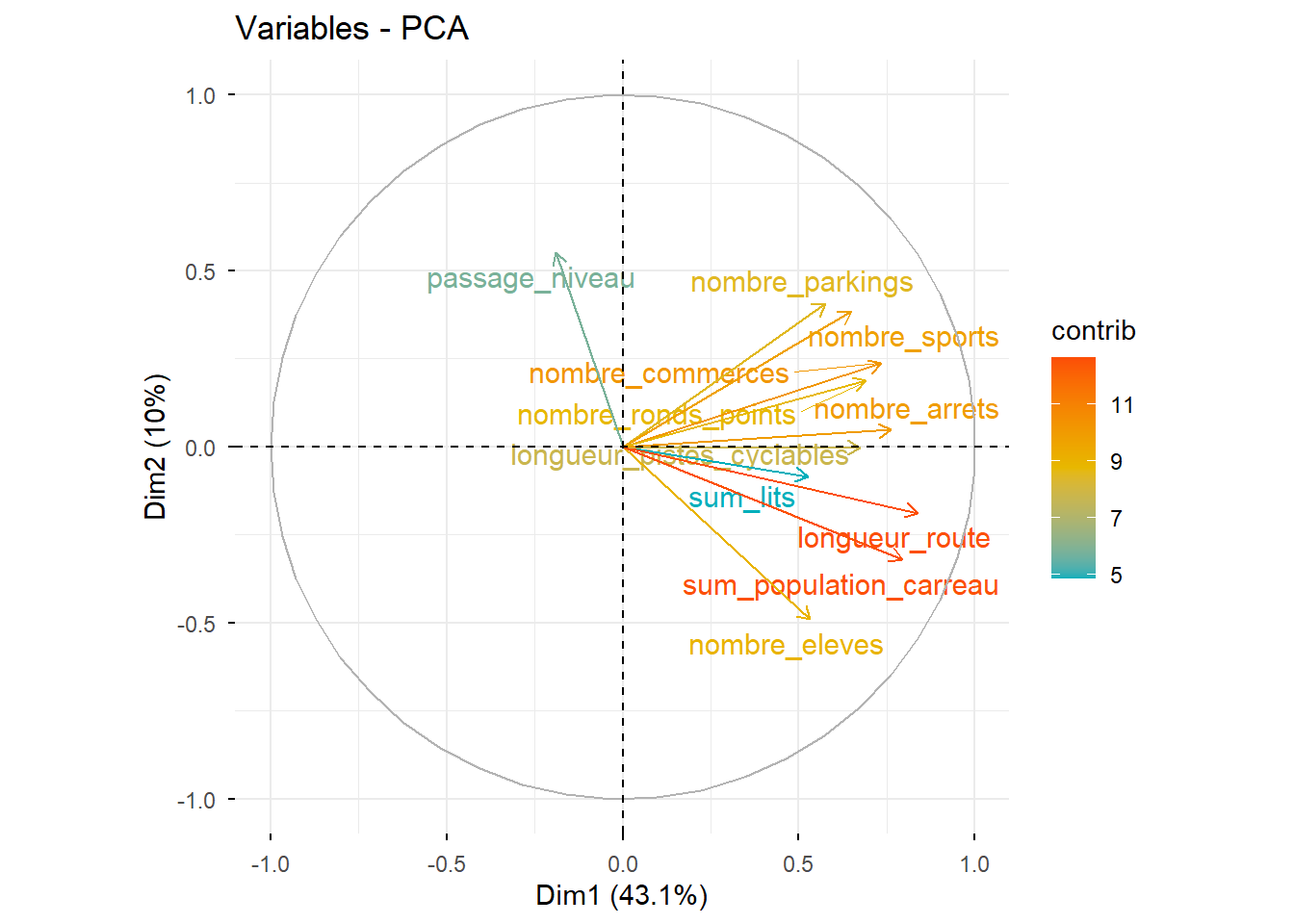
# Graphique des individus
factoextra::fviz_pca_ind(PCA, col.ind = "cos2",
gradient.cols = c("#00AFBB", "#E7B800", "#FC4E07"),
repel = TRUE)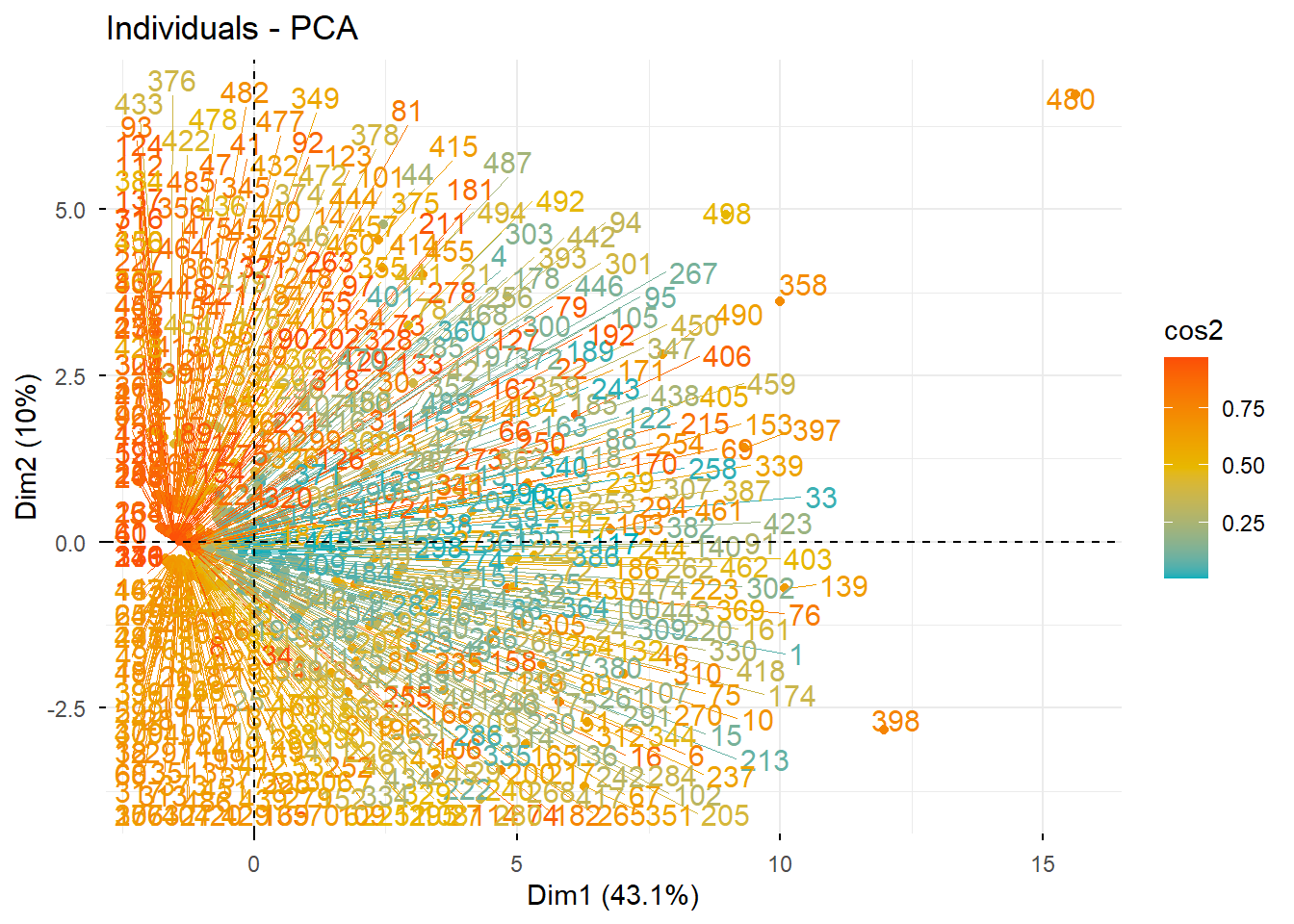
## eigenvalue percentage of variance cumulative percentage of variance
## comp 1 4.7371548 43.065044 43.06504
## comp 2 1.0959291 9.962992 53.02804
## comp 3 1.0287654 9.352413 62.38045
## comp 4 0.9299004 8.453640 70.83409
## comp 5 0.7421077 6.746434 77.58052
## comp 6 0.6314726 5.740660 83.32118
## comp 7 0.5557962 5.052692 88.37387
## comp 8 0.4673489 4.248626 92.62250
## comp 9 0.4118871 3.744429 96.36693
## comp 10 0.2801946 2.547223 98.91415
## comp 11 0.1194432 1.085847 100.00000# Contribution de chaque variable aux deux premiers axes
factoextra::fviz_contrib(PCA, choice = "var", axes = 1) # axe 1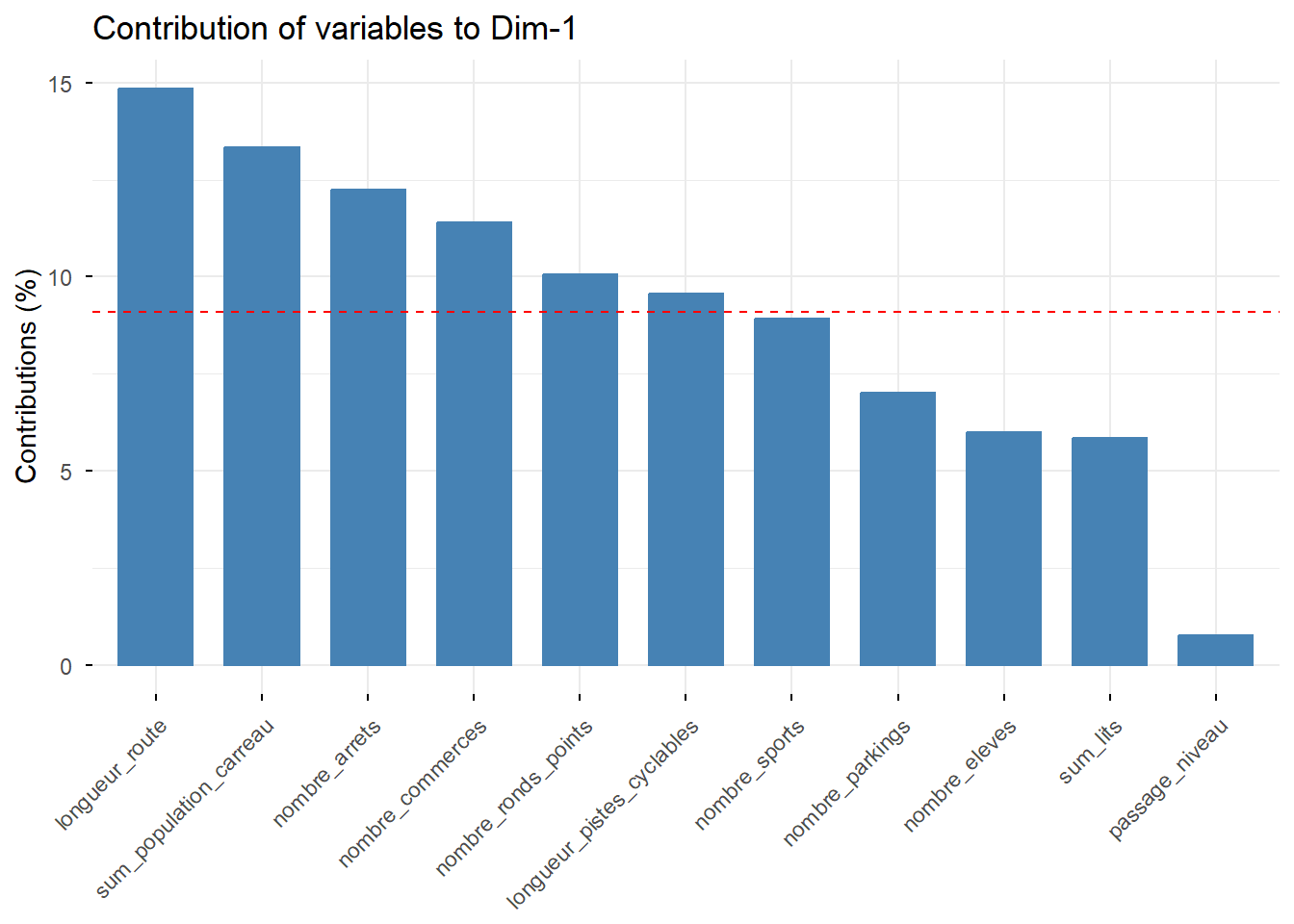
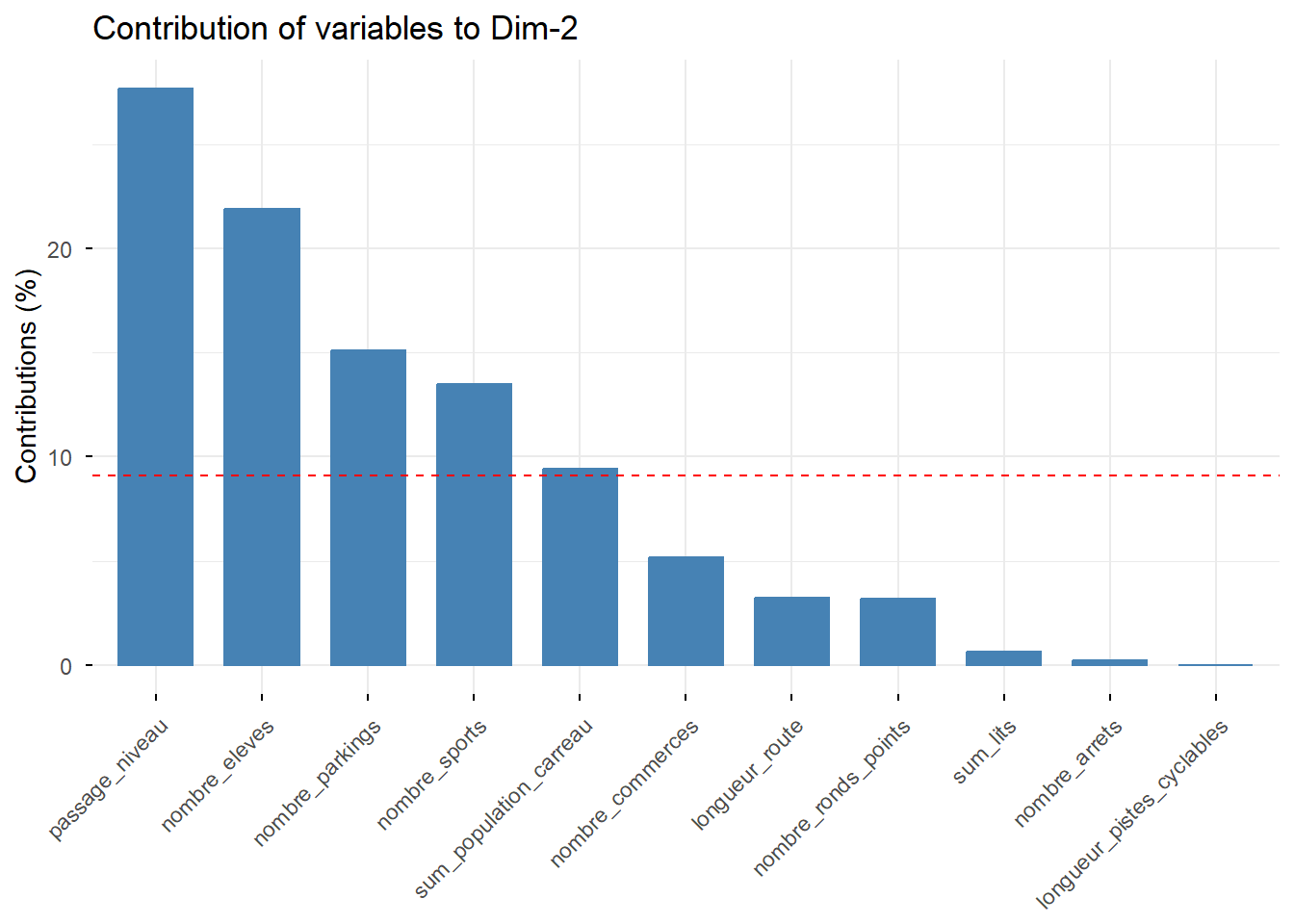
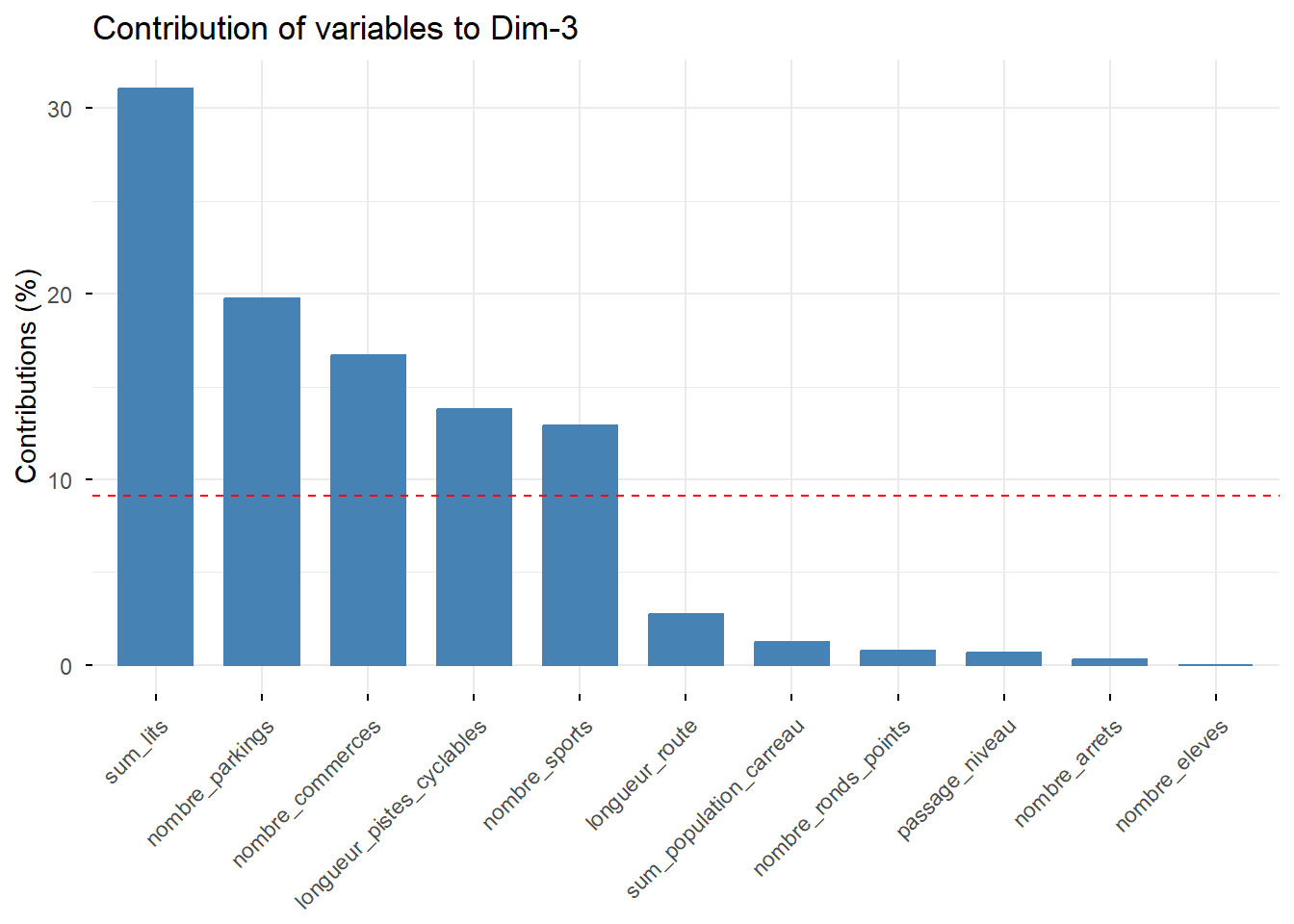
8 - Classification ascendante hiérarchique et cartographie
# CAH sur les scores des individus de l'ACP ----
hc <- HCPC(PCA, nb.clust = 3, graph = FALSE)
# Visualiser les dendrogrammes
fviz_dend(hc, cex = 0.5)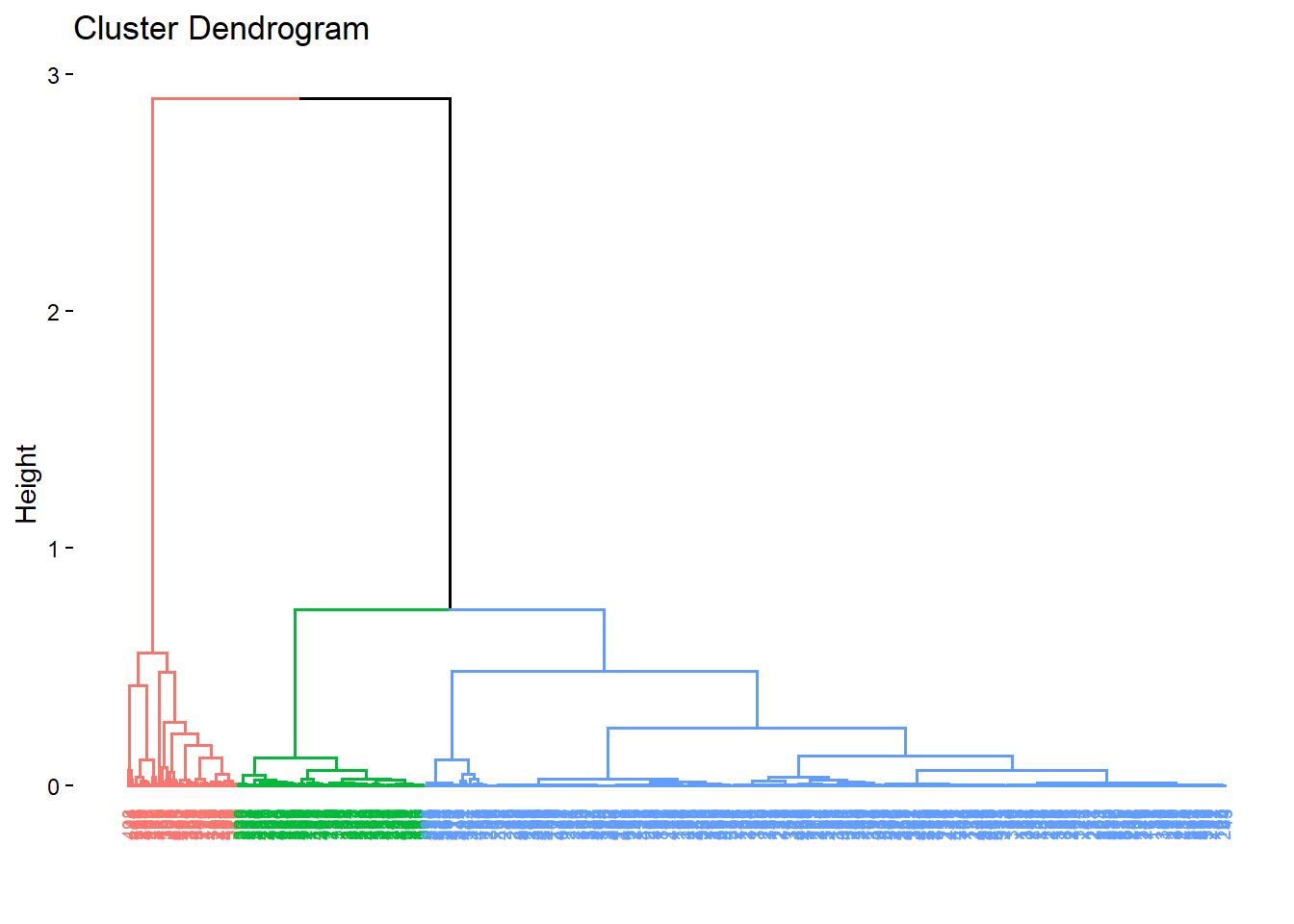
# Visualiser les individus dans le plan factoriel avec une indication de leur cluster
fviz_cluster(hc, geom = "point")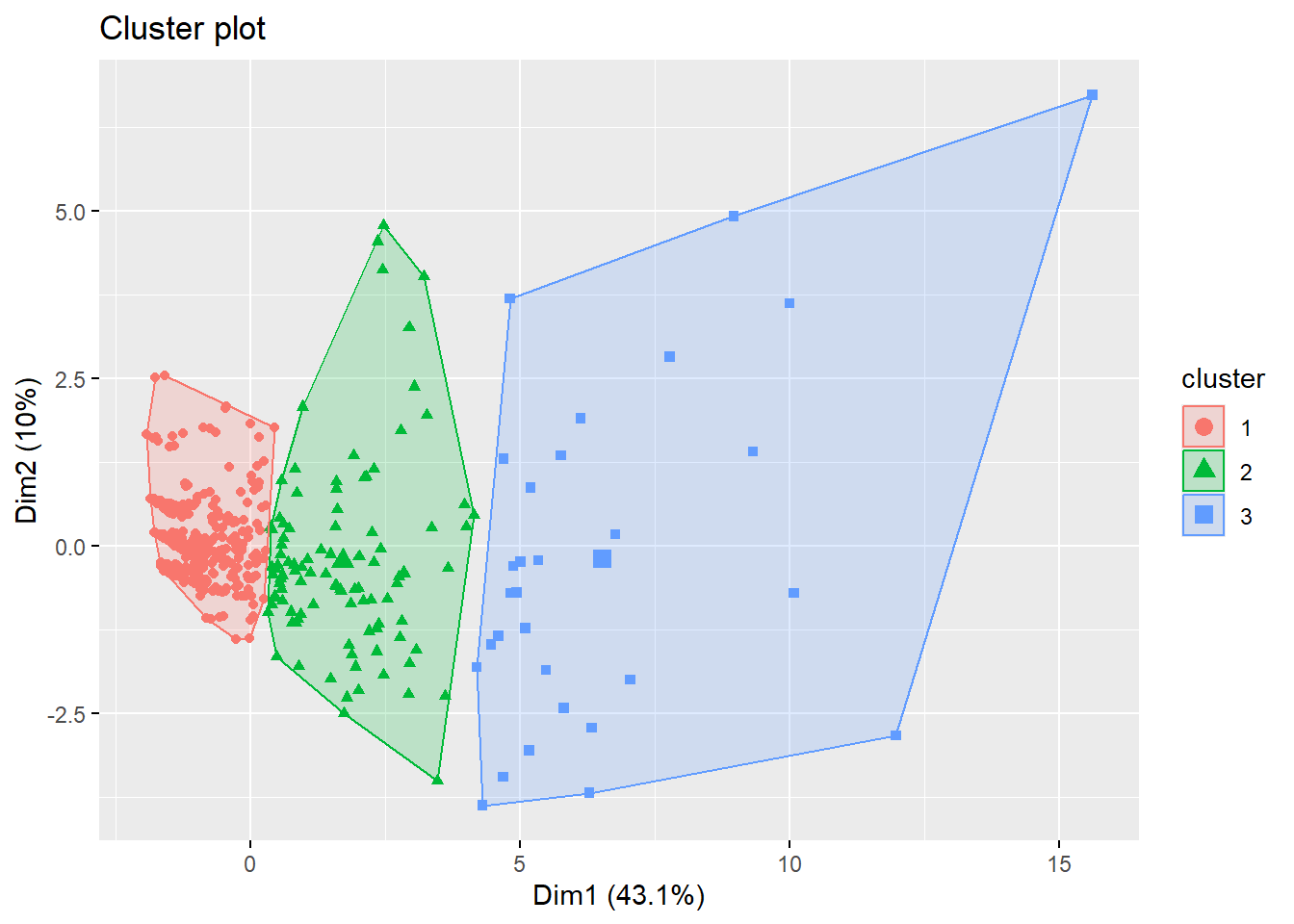
# Extraction des clusters attribués à chaque observation
clusters <- hc$data.clust$clust
length(clusters)## [1] 498# Assurez-vous que vos données originales ont un identifiant unique pour chaque observation
# Ajouter les affectations de cluster à vos données originales
nrow(all_data_filter)## [1] 498## ℹ tmap modes "plot" - "view"tm_basemap(c(leaflet::providers$Esri.WorldTopoMap,
leaflet::providers$OpenStreetMap,
leaflet::providers$Esri.WorldImageryiders,
leaflet::providers$GeoportailFrance.orthos)) +
tm_shape(all_data_filter) +
tm_dots(col = "cluster", palette = "Set1", title = "Cluster") +
tm_basemap(server = "OpenStreetMap") +
tm_layout(legend.position = c("left", "bottom"))##
## ── tmap v3 code detected ───────────────────────────────────────────────────────
## [v3->v4] `tm_tm_dots()`: migrate the argument(s) related to the scale of the
## visual variable `fill` namely 'palette' (rename to 'values') to fill.scale =
## tm_scale(<HERE>).[tm_dots()] Argument `title` unknown.[cols4all] color palettes: use palettes from the R package cols4all. Run
## `cols4all::c4a_gui()` to explore them. The old palette name "Set1" is named
## "brewer.set1"9 - BOXPLOTS
donnees_longues <- tidyr::pivot_longer(all_data_filter,
cols = c(
# sum_population,
# sum_population_active,
sum_lits,
longueur_route,
# nb_intersections,
# reseau_pedestre,
longueur_pistes_cyclables,
nombre_arrets,
nombre_parkings,
nombre_commerces,
# nombre_sante,
# nombre_loisirs,
# nombre_restauration,
nombre_sports,
nombre_ronds_points,
nombre_eleves,
# ZA,
passage_niveau,
sum_population_carreau,
PNR_OK),
names_to = "Variable",
values_to = "Valeur")ggplot(donnees_longues, aes(x = as.factor(cluster), y = Valeur, fill = as.factor(cluster))) +
geom_boxplot() +
facet_wrap(~ Variable, scales = "free_y") + # Crée un panel pour chaque variable
labs(x = "Cluster", y = "Valeur") +
scale_fill_brewer(palette = "Pastel1") + # Utiliser une palette de couleurs
theme_minimal() +
theme(legend.title = element_blank(), axis.text.x = element_text(angle = 45, hjust = 1)) # Personnalise le graphique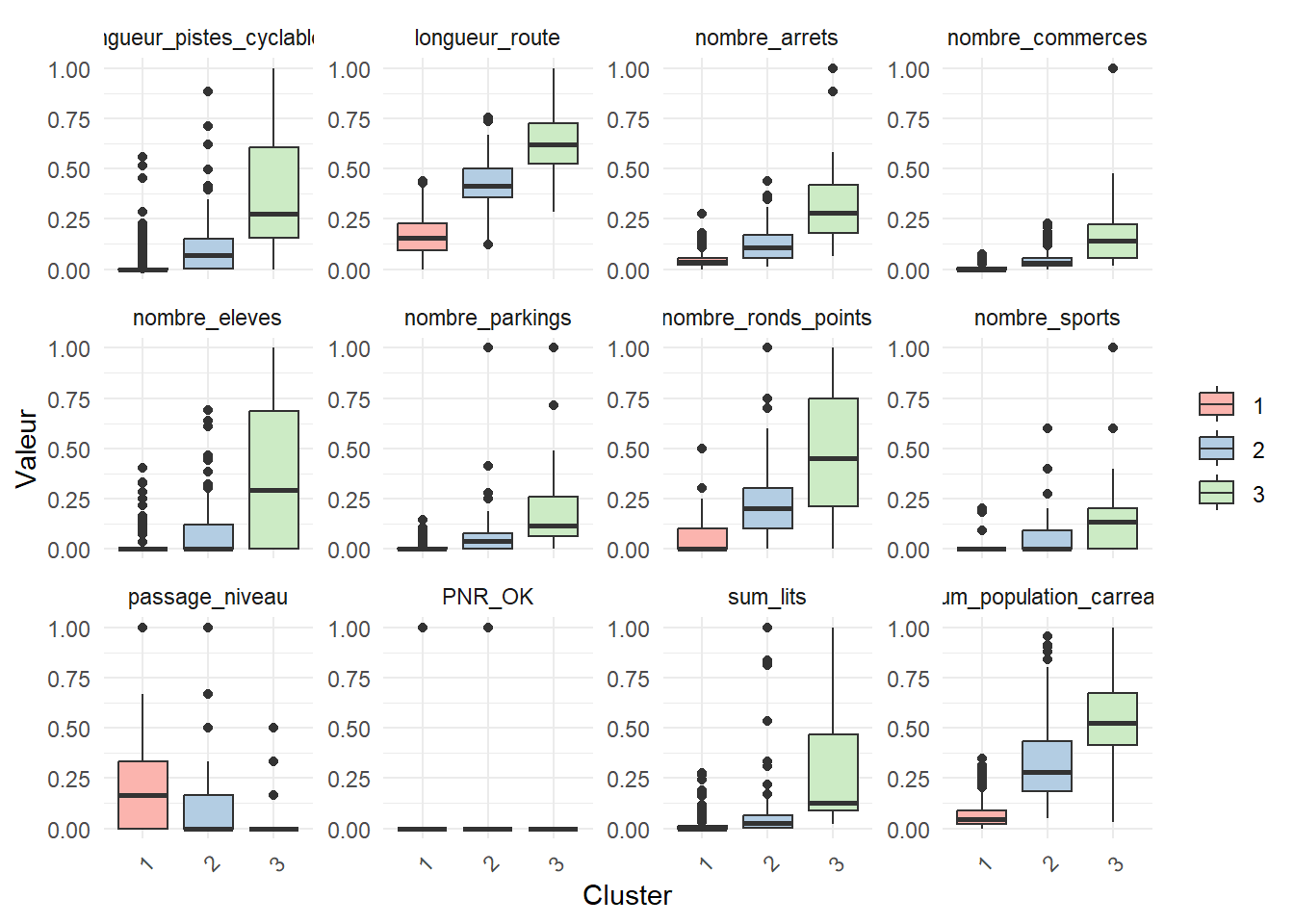
CORRELATION
Corrélation entre les variables dépendantes
# Chargement des données
all_data<- sf::st_read('processed_data/all_data_standardized_stpol_foot_10min_pop_carreau_20240307.gpkg')## Reading layer `all_data_standardized_rennes_stpol_10min_pop_carreau_20240307' from data source `C:\docs\rprojects\database_sf\processed_data\all_data_standardized_stpol_foot_10min_pop_carreau_20240307.gpkg'
## using driver `GPKG'
## Simple feature collection with 140 features and 23 fields
## Geometry type: POINT
## Dimension: XY
## Bounding box: xmin: 603303 ymin: 7019253 xmax: 683443.5 ymax: 7048245
## Projected CRS: RGF93 v1 / Lambert-93## [1] "pk" "ID_number"
## [3] "sum_population" "sum_population_active"
## [5] "sum_lits" "longueur_route"
## [7] "nb_intersections" "reseau_pedestre"
## [9] "longueur_pistes_cyclables" "nombre_arrets"
## [11] "nombre_parkings" "nombre_commerces"
## [13] "nombre_sante" "nombre_loisirs"
## [15] "nombre_restauration" "nombre_sports"
## [17] "nombre_ronds_points" "nombre_eleves"
## [19] "ZA" "passage_niveau"
## [21] "sum_population_carreau" "total_sum"
## [23] "total_sum_allegee" "geom"data_select <- all_data %>%
select(sum_population,
sum_population_carreau,
sum_population_active,
sum_lits,
longueur_route,
nb_intersections,
reseau_pedestre,
longueur_pistes_cyclables,
nombre_arrets,
nombre_parkings,
nombre_commerces,
nombre_sante,
nombre_loisirs,
nombre_restauration,
nombre_sports,
nombre_ronds_points,
nombre_eleves,
ZA,
passage_niveau
) %>%
st_drop_geometry()Coefficient de corrélation
Ci-dessous avec la méthode de Pearson (méthode par défaut). La
corrélation de Pearson est appropriée pour des données continues et
normalement distribuées, mesurant les relations linéaires.
Elle mesure le degré de relation linéaire entre deux variables
quantitatives. En d’autres termes, elle cherche à déterminer si, lorsque
l’une des variables augmente ou diminue, l’autre variable tend également
à augmenter ou diminuer selon un modèle prévisible et constant, ce qui
serait caractéristique d’une relation linéaire. Un coefficient de
corrélation proche de 1 ou -1 indique une forte relation linéaire,
tandis qu’un coefficient proche de 0 suggère une faible ou aucune
relation linéaire.
La formule pour calculer le coefficient de corrélation de Pearson, \(r\), entre deux variables \(X\) et \(Y\) est :
\[ r = \frac{\sum (X_i - \overline{X})(Y_i - \overline{Y})}{\sqrt{\sum (X_i - \overline{X})^2 \sum (Y_i - \overline{Y})^2}} \]
Où: - \(X_i\) et \(Y_i\) sont les valeurs individuelles des
variables \(X\) et \(Y\),
- \(\overline{X}\) et \(\overline{Y}\) sont les moyennes de \(X\) et \(Y\),
Matrice de corrélation
mcor <- cor(data_select,
use = "complete.obs",
method = 'pearson')
corrplot::corrplot(mcor,
type="upper",
order="hclust",
tl.col="black")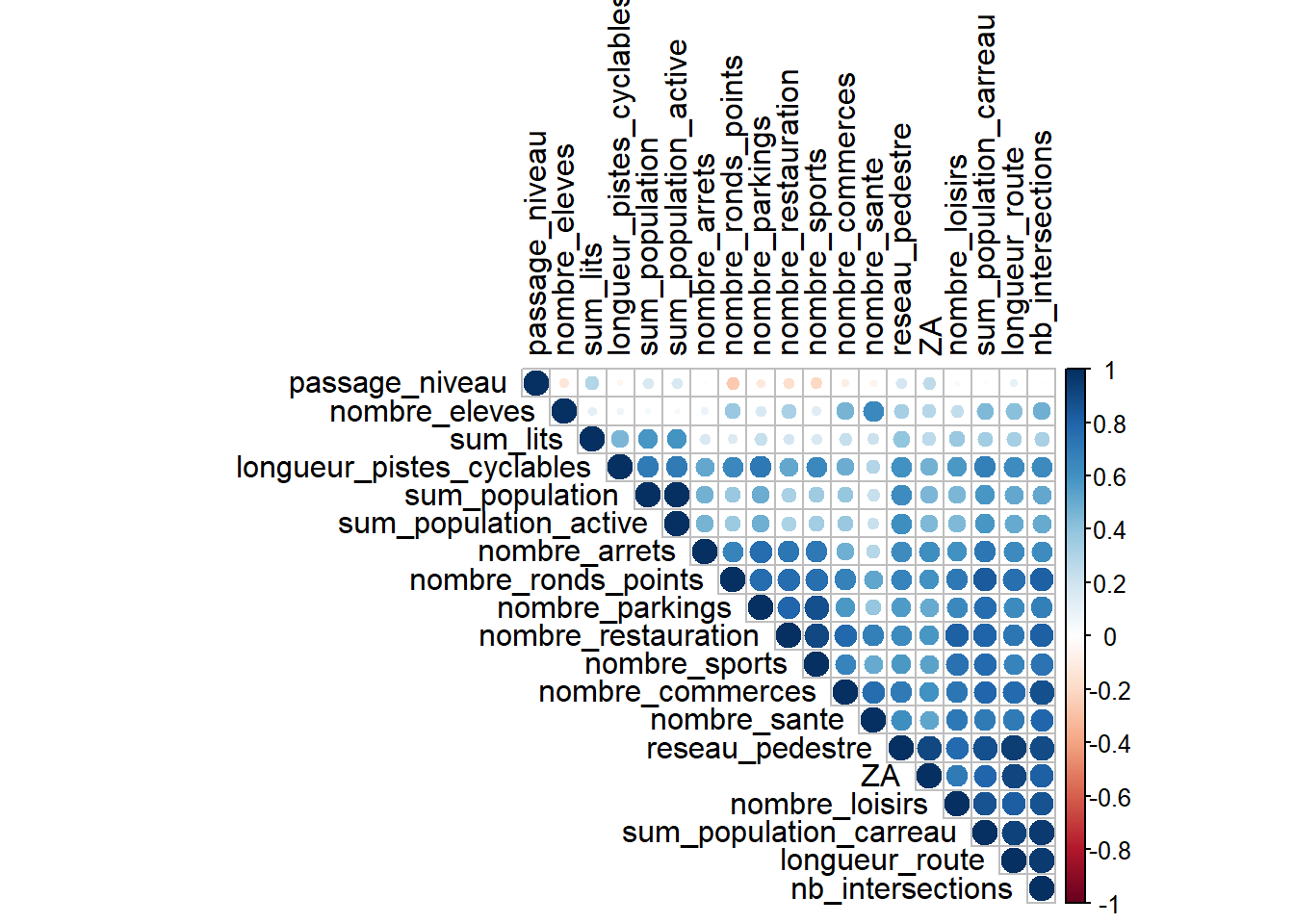 La méthode de Spearman est une mesure de corrélation de rang qui peuvent
être plus appropriées pour des données non normales ou pour des
relations non linéaires.
La méthode de Spearman est une mesure de corrélation de rang qui peuvent
être plus appropriées pour des données non normales ou pour des
relations non linéaires.
mcor <- cor(data_select,
use = "complete.obs",
method = 'spearman')
corrplot::corrplot(mcor,
type="upper",
order="hclust",
tl.col="black")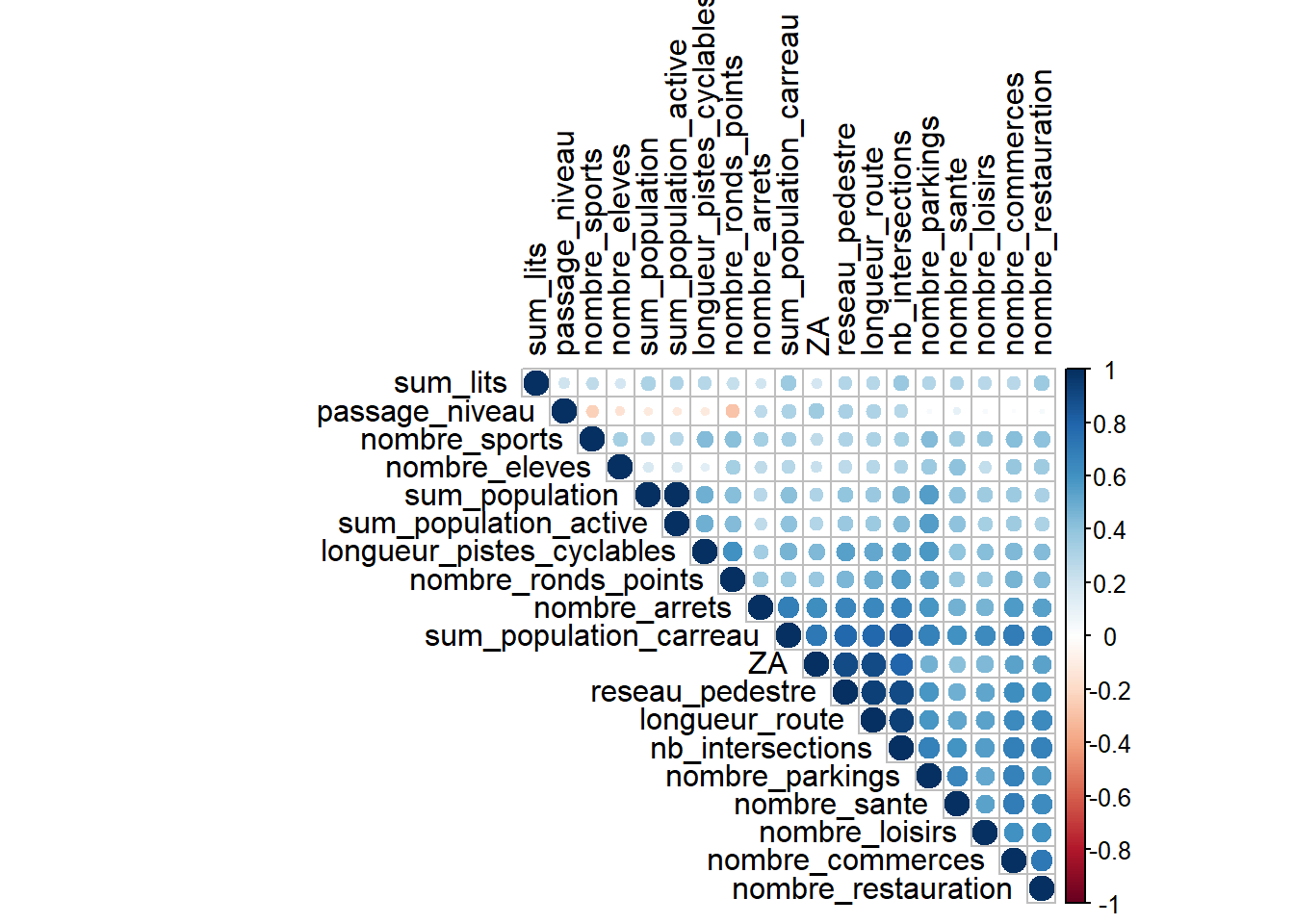
Approche pour Réduire les Variables
Nous commençons par identifier les variables qui ont des corrélations très élevées avec d’autres, pour réduire la redondance.
Fortes Corrélations
Des corrélations très élevées (proches de 1 ou -1) entre deux variables
suggèrent une redondance potentielle. Par exemple,
sum_population et
sum_population_active ont une corrélation de presque 1,
ce qui indique une possible redondance entre ces deux variables. Si une
variable est fortement corrélée avec plusieurs autres variables, cela
peut indiquer qu’elle n’apporte pas d’informations uniques à l’ensemble
de données. Dans notre cas, certaines variables comme
longueur_route et nb_intersections ont
des corrélations élevées avec plusieurs autres variables, suggérant
qu’elles partagent des informations communes.
Variables à Considérer pour Réduction
Variables avec faible corrélation avec les autres : Par exemple,
passage_niveau montre des corrélations très faibles ou
négatives avec la plupart des autres variables, ce qui peut suggérer
qu’elle est moins liée à l’ensemble des variables étudiées.
Nous souhaitons maintenir une diversité en incluant des variables
représentant différents aspects de l’urbanisme et des services, comme
par exemple le nombre de stuctures touristiques ou le nombre de
commerces. Ainsi, nous conservons :
- Population totale : Pour représenter la démographie
- Nombre de structures de tourisme : Pour évaluer l’accès aux soins
espaces de loisirs
- Les arrêts de transport en commun : Reflète l’accessibilité et la
qualité de l’infrastructure de transport public, un facteur important
pour la mobilité urbaine et périurbaine
- Nombre de commerces : Pour refléter l’activité économique
locale
- Nombre d’élèves : Donne une idée de la population scolaire,
pertinent pour évaluer les besoins en éducation et les dynamiques
jeunesse du territoire
- Le nombre de passage à niveau : Signe de l’interconnexion entre le
réseau ferroviaire et la trame urbaine, important pour comprendre les
enjeux de mobilité et de sécurité
- Les zones artificialisées : Pour mesurer le potentiel urbain
- La pente (dans les données sur le vélo) : Évaluation de la difficulté de déplacement en vélo, un aspect fondamental pour promouvoir la mobilité douce et planifier des infrastructures cyclables adaptées

Tableau 1 : Liste des variables sélectionnées
Variance inflation factor (VIF)
Le VIF quantifie combien la variance des coefficients de régression est augmentée en raison de la colinéarité. Il est utilisé pour détecter la multicolinéarité entre plusieurs variables indépendantes.
Il permet de détecter si 2 valeurs contiennent les mêmes informations. Si c’est le cas, il est possible de n’en conserver qu’une seule pour limiter la colinéarité et son influence sur la variance totale.
L’équation du Variance Inflation Factor (VIF) est donnée par :
\[ \text{VIF}_i = \frac{1}{1 - R_i^2} \]
où :
- \(\text{VIF}_i\) est le Variance
Inflation Factor pour le \(i\)-ème
prédicteur.
- \(R_i^2\) est le coefficient de
détermination obtenu en régressant le \(i\)-ème prédicteur sur tous les autres
prédicteurs du modèle.
Cette équation montre que le VIF mesure l’inflation de la variance d’un coefficient de régression en raison de la colinéarité entre les prédicteurs.
ACP
Rappel sur l’ACP.
L’analyse multivariée permet d’étudier les relations entre plusieurs variables et dispose de plusieurs outils statistiques.
Les analyses factorielles font partie de ces
outils.
4 grands types peuvent être utilisés :
* l’analyse en composantes principales (ACP) : L’ACP est utile face à
des variables quantitatives
* l’analyse factorielle des correspondances (AFC) : L’AFC est utile face
à deux variables qualitatives
* l’analyse des correspondances multiples (ACM) : L’ACM est utile face à
plusieurs variables qualitatives
* l’analyse factorielle des correspondances mixtes ou des données mixtes
(AFCM ou AFDM) : L’AFCM prend en compte à la fois des variables
quantitatives et qualitatives
Ainsi, l’analyse en composantes principales (ACP) permet de résumer l’information de plusieurs variables quantitatives. L’information est résumée en un plus petit nombre de “composantes”, qui sont des combinaisons des variables initiales. Les composantes obtenues sont non-corrélées entre elles.
Pour réaliser l’ACP nous utilisons la méthode du package
FactomineR.
Nous utilisons également le package factoextra pour la représentation
graphique.
# Packages
pacman::p_load(sf, dplyr, FactoMineR, factoextra)
# Data
all_data<- sf::st_read('processed_data/all_data_standardized_stpol_foot_10min_pop_carreau_20240307.gpkg')## Reading layer `all_data_standardized_rennes_stpol_10min_pop_carreau_20240307' from data source `C:\docs\rprojects\database_sf\processed_data\all_data_standardized_stpol_foot_10min_pop_carreau_20240307.gpkg'
## using driver `GPKG'
## Simple feature collection with 140 features and 23 fields
## Geometry type: POINT
## Dimension: XY
## Bounding box: xmin: 603303 ymin: 7019253 xmax: 683443.5 ymax: 7048245
## Projected CRS: RGF93 v1 / Lambert-93## [1] "pk" "ID_number"
## [3] "sum_population" "sum_population_active"
## [5] "sum_lits" "longueur_route"
## [7] "nb_intersections" "reseau_pedestre"
## [9] "longueur_pistes_cyclables" "nombre_arrets"
## [11] "nombre_parkings" "nombre_commerces"
## [13] "nombre_sante" "nombre_loisirs"
## [15] "nombre_restauration" "nombre_sports"
## [17] "nombre_ronds_points" "nombre_eleves"
## [19] "ZA" "passage_niveau"
## [21] "sum_population_carreau" "total_sum"
## [23] "total_sum_allegee" "geom"data_select <- all_data %>%
select(sum_population,
sum_population_active,
sum_lits,
longueur_route,
nb_intersections,
reseau_pedestre,
longueur_pistes_cyclables,
nombre_arrets,
nombre_parkings,
nombre_commerces,
nombre_sante,
nombre_loisirs,
nombre_restauration,
nombre_sports,
nombre_ronds_points,
nombre_eleves,
passage_niveau,
ZA) %>%
st_drop_geometry()
glimpse(data_select)## Rows: 140
## Columns: 18
## $ sum_population <dbl> 2.3485879, 2.5887191, 2.7566048, 0.3531290, …
## $ sum_population_active <dbl> 2.3243714, 2.5589343, 2.7410136, 0.3871755, …
## $ sum_lits <dbl> 0.8932275, 0.8932275, 0.8932275, -0.5848741,…
## $ longueur_route <dbl> 5.16867646, 3.10459511, 0.06961055, 1.458407…
## $ nb_intersections <dbl> 5.09987535, 3.42890606, -0.02617106, 0.70487…
## $ reseau_pedestre <dbl> 4.44733819, 2.50619176, 0.36621457, 2.893083…
## $ longueur_pistes_cyclables <dbl> 5.19569185, 4.72415850, -0.29324894, 0.09455…
## $ nombre_arrets <dbl> 7.4673409, 1.9713200, 0.9566700, 0.4493450, …
## $ nombre_parkings <dbl> 7.5419708169, 3.8195204239, -0.2836575398, -…
## $ nombre_commerces <dbl> 3.18472950, 4.82192214, -0.36252123, -0.0896…
## $ nombre_sante <dbl> 1.44786385, 1.74377763, -0.32761883, -0.3276…
## $ nombre_loisirs <dbl> 6.76906609, 2.27561302, -0.42045882, 0.47823…
## $ nombre_restauration <dbl> 7.05862493, 1.84712880, -0.12964559, -0.1296…
## $ nombre_sports <dbl> 7.8168892, 3.8082281, -0.2004331, -0.2004331…
## $ nombre_ronds_points <dbl> 7.6031051, 3.6313338, -0.3404375, 0.4539167,…
## $ nombre_eleves <dbl> -0.1493615, -0.1493615, -0.1493615, -0.14936…
## $ passage_niveau <dbl> -1.16291821, -1.16291821, -0.07024338, -1.16…
## $ ZA <dbl> 4.9050264, 1.9417255, 0.1296123, 1.9693857, …## sum_population sum_population_active sum_lits
## sum_population 1.00000000 0.99924452 0.5893858
## sum_population_active 0.99924452 1.00000000 0.5970567
## sum_lits 0.58938584 0.59705672 1.0000000
## longueur_route 0.51595721 0.50934369 0.3310645
## nb_intersections 0.51573488 0.50758990 0.3248075
## reseau_pedestre 0.62251289 0.61586826 0.3986321
## longueur_pistes_cyclables 0.70085972 0.70353524 0.4589517
## nombre_arrets 0.47642887 0.46292631 0.1609571
## nombre_parkings 0.49372272 0.48691829 0.2361889
## nombre_commerces 0.38658626 0.37958365 0.2340942
## nombre_sante 0.22815439 0.22261811 0.2101464
## nombre_loisirs 0.45276620 0.44955265 0.3741853
## nombre_restauration 0.32226623 0.31477453 0.1898868
## nombre_sports 0.35619350 0.34890209 0.1642547
## nombre_ronds_points 0.37215636 0.36386084 0.1575403
## nombre_eleves 0.04594885 0.04200966 0.1126870
## passage_niveau 0.16093168 0.16483300 0.2967487
## ZA 0.45497554 0.44913702 0.2675785
## longueur_route nb_intersections reseau_pedestre
## sum_population 0.5159572 0.51573488 0.6225129
## sum_population_active 0.5093437 0.50758990 0.6158683
## sum_lits 0.3310645 0.32480750 0.3986321
## longueur_route 1.0000000 0.95834529 0.9458683
## nb_intersections 0.9583453 1.00000000 0.8974281
## reseau_pedestre 0.9458683 0.89742806 1.0000000
## longueur_pistes_cyclables 0.6212782 0.63533071 0.6099911
## nombre_arrets 0.6304407 0.62809750 0.6204415
## nombre_parkings 0.6341161 0.68834338 0.5679835
## nombre_commerces 0.7716204 0.87746876 0.7013466
## nombre_sante 0.7011284 0.79875708 0.6151281
## nombre_loisirs 0.8290609 0.86222682 0.7788058
## nombre_restauration 0.7261066 0.81896695 0.6320947
## nombre_sports 0.6691651 0.73713722 0.5762619
## nombre_ronds_points 0.7597996 0.81215974 0.6631809
## nombre_eleves 0.4103867 0.48575463 0.3354086
## passage_niveau 0.1012891 -0.01765514 0.1825102
## ZA 0.9159476 0.81378985 0.9086366
## longueur_pistes_cyclables nombre_arrets
## sum_population 0.70085972 0.47642887
## sum_population_active 0.70353524 0.46292631
## sum_lits 0.45895172 0.16095714
## longueur_route 0.62127818 0.63044065
## nb_intersections 0.63533071 0.62809750
## reseau_pedestre 0.60999105 0.62044148
## longueur_pistes_cyclables 1.00000000 0.51133285
## nombre_arrets 0.51133285 1.00000000
## nombre_parkings 0.71988456 0.76494600
## nombre_commerces 0.49315849 0.48574788
## nombre_sante 0.29697118 0.28795712
## nombre_loisirs 0.57522343 0.60002434
## nombre_restauration 0.51976910 0.72124036
## nombre_sports 0.64206793 0.71983990
## nombre_ronds_points 0.64625057 0.66965777
## nombre_eleves 0.07767039 0.08170547
## passage_niveau -0.05436620 0.01982639
## ZA 0.47726480 0.61615733
## nombre_parkings nombre_commerces nombre_sante
## sum_population 0.4937227 0.38658626 0.22815439
## sum_population_active 0.4869183 0.37958365 0.22261811
## sum_lits 0.2361889 0.23409417 0.21014637
## longueur_route 0.6341161 0.77162043 0.70112840
## nb_intersections 0.6883434 0.87746876 0.79875708
## reseau_pedestre 0.5679835 0.70134662 0.61512812
## longueur_pistes_cyclables 0.7198846 0.49315849 0.29697118
## nombre_arrets 0.7649460 0.48574788 0.28795712
## nombre_parkings 1.0000000 0.57909093 0.38483873
## nombre_commerces 0.5790909 1.00000000 0.76856785
## nombre_sante 0.3848387 0.76856785 1.00000000
## nombre_loisirs 0.6408026 0.72857029 0.71837280
## nombre_restauration 0.7938725 0.78133175 0.68449219
## nombre_sports 0.8707952 0.66652507 0.50563612
## nombre_ronds_points 0.7678163 0.67253213 0.52858386
## nombre_eleves 0.1601140 0.46376846 0.64256178
## passage_niveau -0.1202759 -0.09643249 -0.06504966
## ZA 0.5011603 0.60638970 0.52282748
## nombre_loisirs nombre_restauration nombre_sports
## sum_population 0.45276620 0.3222662 0.3561935
## sum_population_active 0.44955265 0.3147745 0.3489021
## sum_lits 0.37418535 0.1898868 0.1642547
## longueur_route 0.82906090 0.7261066 0.6691651
## nb_intersections 0.86222682 0.8189669 0.7371372
## reseau_pedestre 0.77880583 0.6320947 0.5762619
## longueur_pistes_cyclables 0.57522343 0.5197691 0.6420679
## nombre_arrets 0.60002434 0.7212404 0.7198399
## nombre_parkings 0.64080258 0.7938725 0.8707952
## nombre_commerces 0.72857029 0.7813317 0.6665251
## nombre_sante 0.71837280 0.6844922 0.5056361
## nombre_loisirs 1.00000000 0.8106949 0.7444830
## nombre_restauration 0.81069492 1.0000000 0.9015159
## nombre_sports 0.74448301 0.9015159 1.0000000
## nombre_ronds_points 0.71607979 0.7627560 0.7559842
## nombre_eleves 0.24913984 0.3232247 0.1333694
## passage_niveau -0.03681151 -0.1716293 -0.2032522
## ZA 0.70181504 0.5802376 0.5334793
## nombre_ronds_points nombre_eleves passage_niveau
## sum_population 0.3721564 0.04594885 0.16093168
## sum_population_active 0.3638608 0.04200966 0.16483300
## sum_lits 0.1575403 0.11268697 0.29674871
## longueur_route 0.7597996 0.41038665 0.10128909
## nb_intersections 0.8121597 0.48575463 -0.01765514
## reseau_pedestre 0.6631809 0.33540865 0.18251024
## longueur_pistes_cyclables 0.6462506 0.07767039 -0.05436620
## nombre_arrets 0.6696578 0.08170547 0.01982639
## nombre_parkings 0.7678163 0.16011398 -0.12027588
## nombre_commerces 0.6725321 0.46376846 -0.09643249
## nombre_sante 0.5285839 0.64256178 -0.06504966
## nombre_loisirs 0.7160798 0.24913984 -0.03681151
## nombre_restauration 0.7627560 0.32322473 -0.17162925
## nombre_sports 0.7559842 0.13336940 -0.20325217
## nombre_ronds_points 1.0000000 0.37300188 -0.26137254
## nombre_eleves 0.3730019 1.00000000 -0.13643833
## passage_niveau -0.2613725 -0.13643833 1.00000000
## ZA 0.6054540 0.28288749 0.25267380
## ZA
## sum_population 0.4549755
## sum_population_active 0.4491370
## sum_lits 0.2675785
## longueur_route 0.9159476
## nb_intersections 0.8137899
## reseau_pedestre 0.9086366
## longueur_pistes_cyclables 0.4772648
## nombre_arrets 0.6161573
## nombre_parkings 0.5011603
## nombre_commerces 0.6063897
## nombre_sante 0.5228275
## nombre_loisirs 0.7018150
## nombre_restauration 0.5802376
## nombre_sports 0.5334793
## nombre_ronds_points 0.6054540
## nombre_eleves 0.2828875
## passage_niveau 0.2526738
## ZA 1.0000000## Warning in geom_bar(stat = "identity", fill = barfill, color = barcolor, :
## Ignoring empty aesthetic: `width`.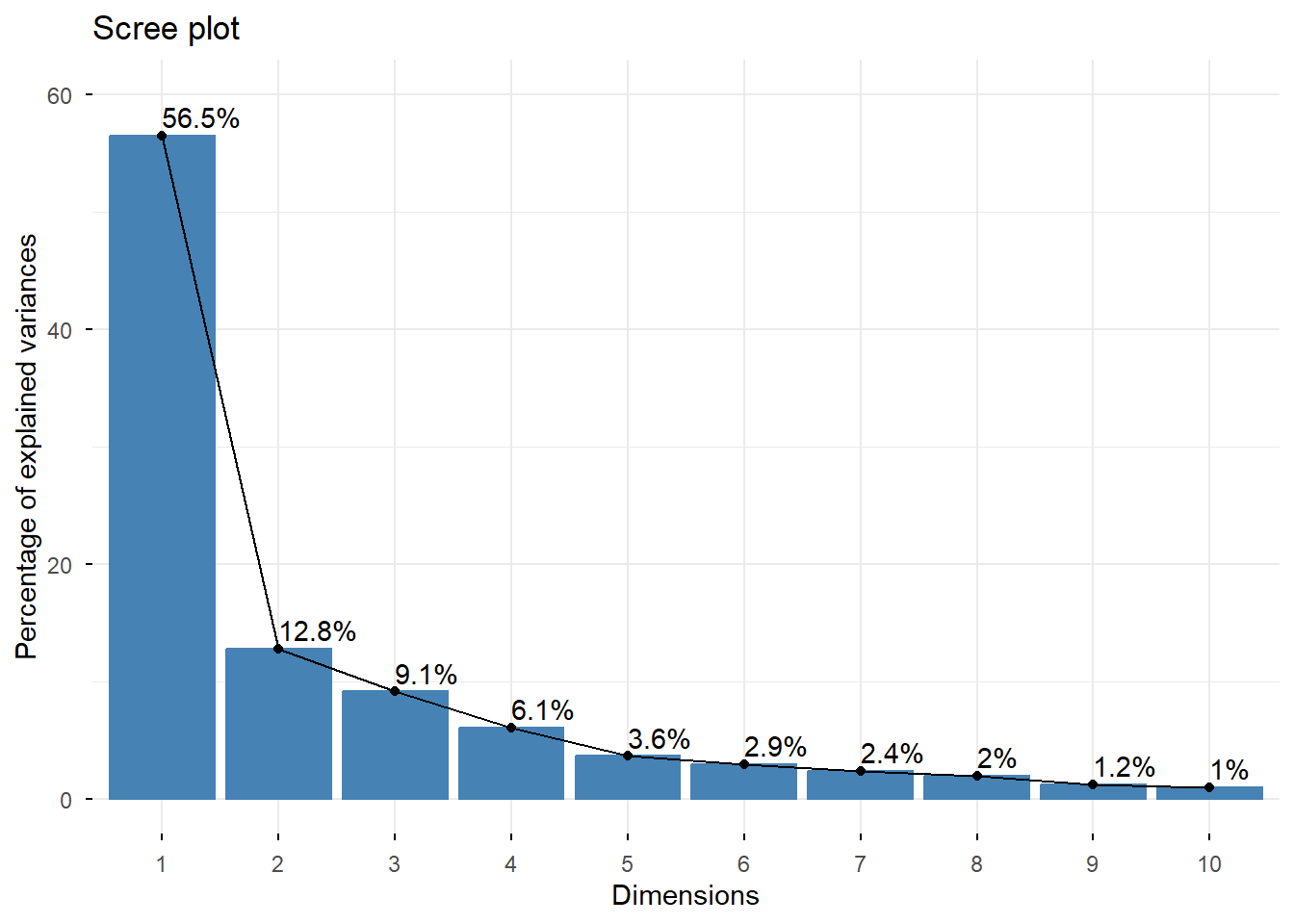
# Cercle des corrélations
fviz_pca_var(PCA, col.var="contrib",
gradient.cols = c("#00AFBB", "#E7B800", "#FC4E07"),
repel = TRUE)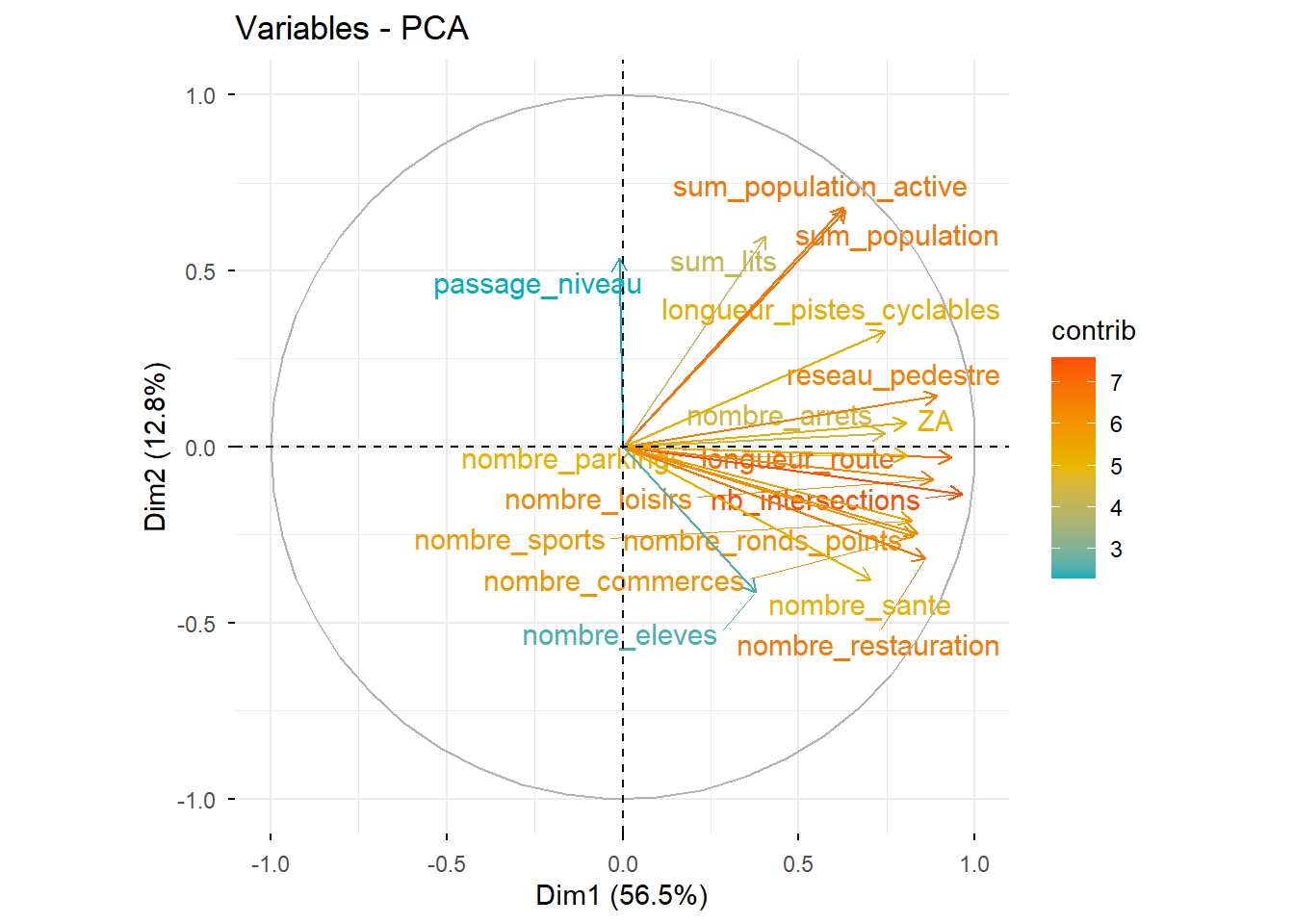
# Graphique des individus
fviz_pca_ind(PCA, col.ind = "cos2",
gradient.cols = c("#00AFBB", "#E7B800", "#FC4E07"),
repel = TRUE)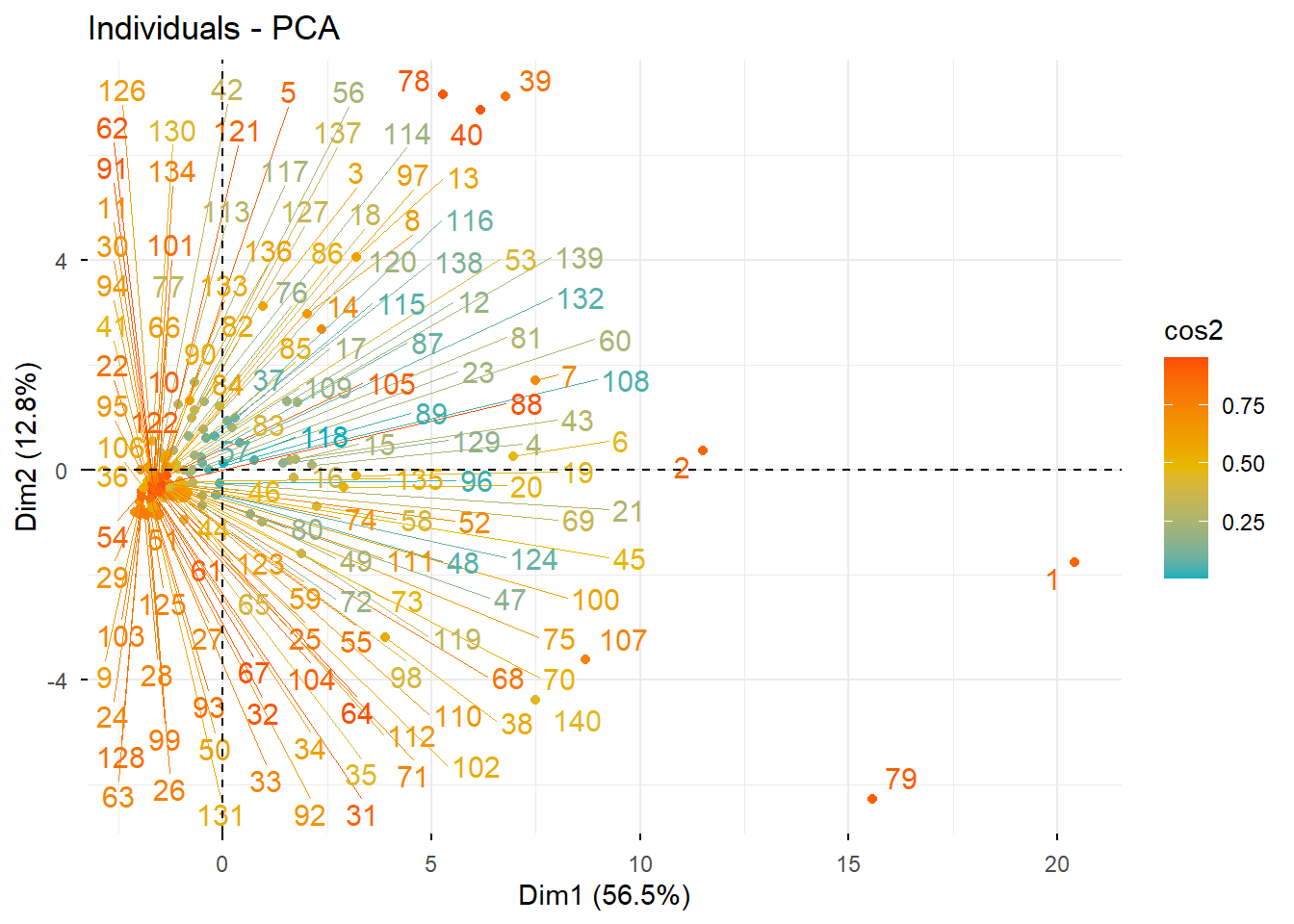
## eigenvalue percentage of variance cumulative percentage of variance
## comp 1 1.017626e+01 56.534764746 56.53476
## comp 2 2.302828e+00 12.793490456 69.32826
## comp 3 1.641325e+00 9.118474164 78.44673
## comp 4 1.090875e+00 6.060418561 84.50715
## comp 5 6.519664e-01 3.622035797 88.12918
## comp 6 5.235041e-01 2.908355903 91.03754
## comp 7 4.289506e-01 2.383059011 93.42060
## comp 8 3.542501e-01 1.968055855 95.38865
## comp 9 2.173461e-01 1.207478567 96.59613
## comp 10 1.777867e-01 0.987703791 97.58384
## comp 11 1.242768e-01 0.690426904 98.27426
## comp 12 8.632486e-02 0.479582561 98.75385
## comp 13 8.363086e-02 0.464615896 99.21846
## comp 14 5.444949e-02 0.302497162 99.52096
## comp 15 4.806500e-02 0.267027772 99.78799
## comp 16 2.873946e-02 0.159663652 99.94765
## comp 17 8.957709e-03 0.049765050 99.99742
## comp 18 4.651475e-04 0.002584153 100.00000# Contribution de chaque variable aux trois premiers axes
fviz_contrib(PCA, choice = "var", axes = 1) # axe 1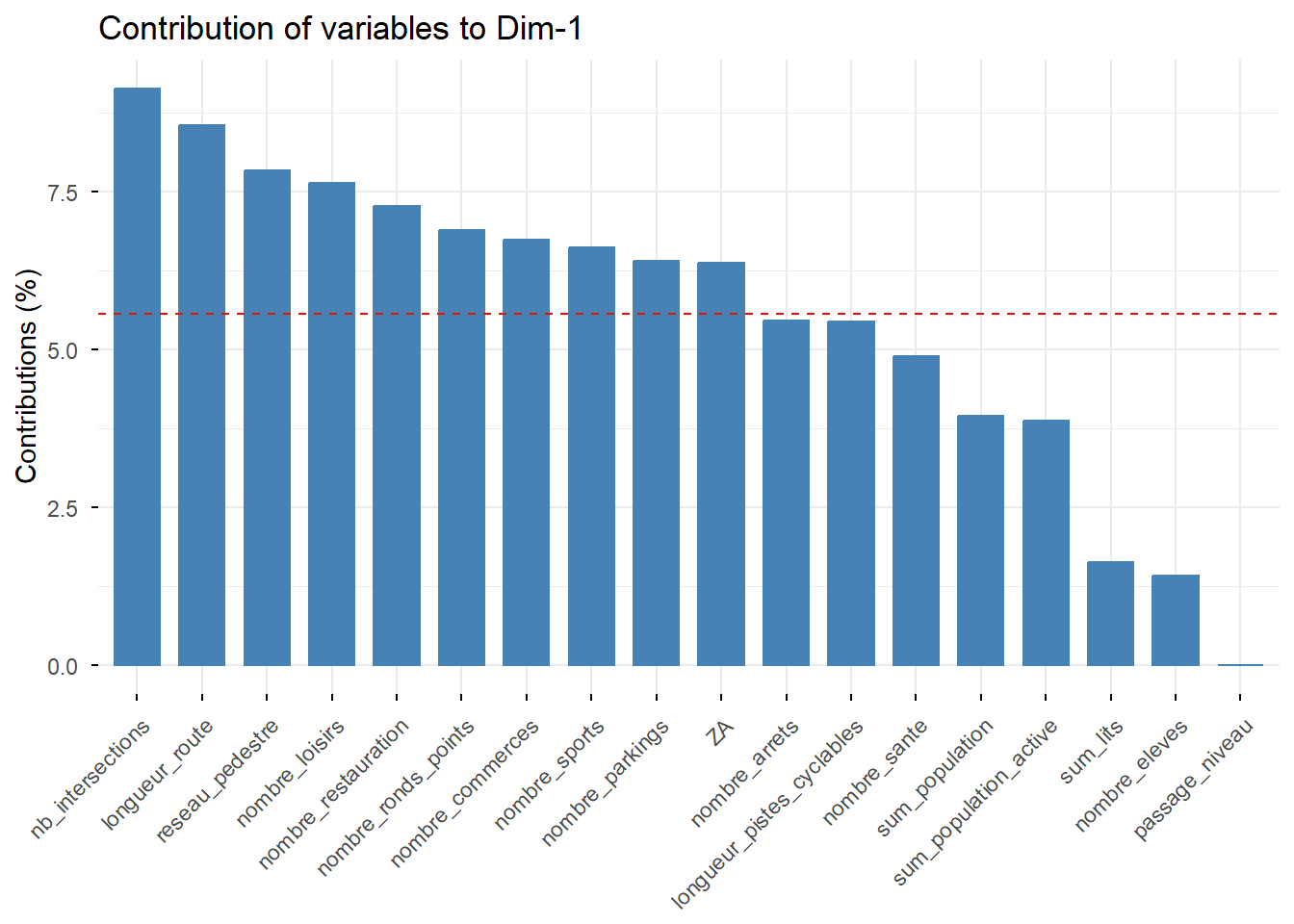
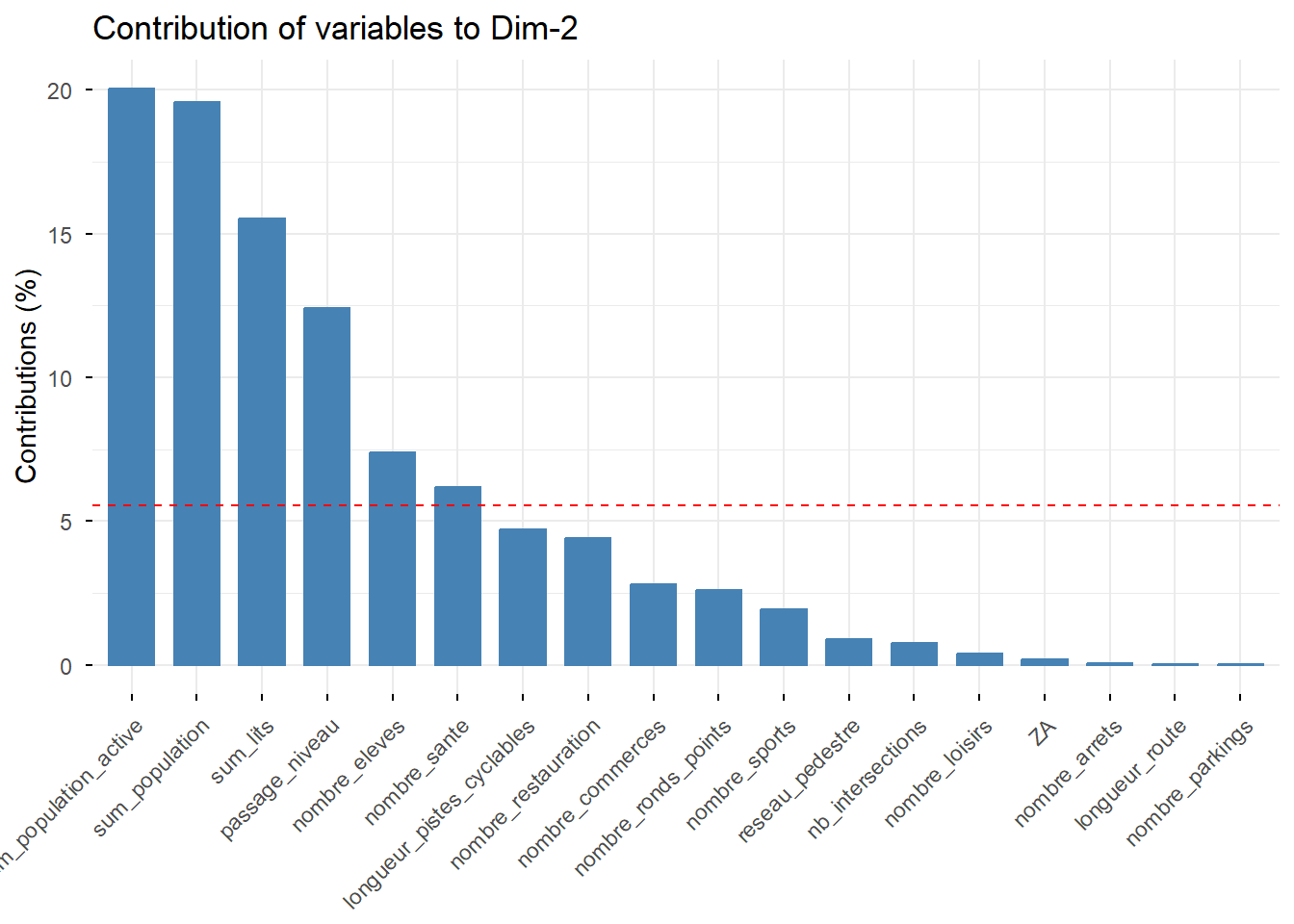
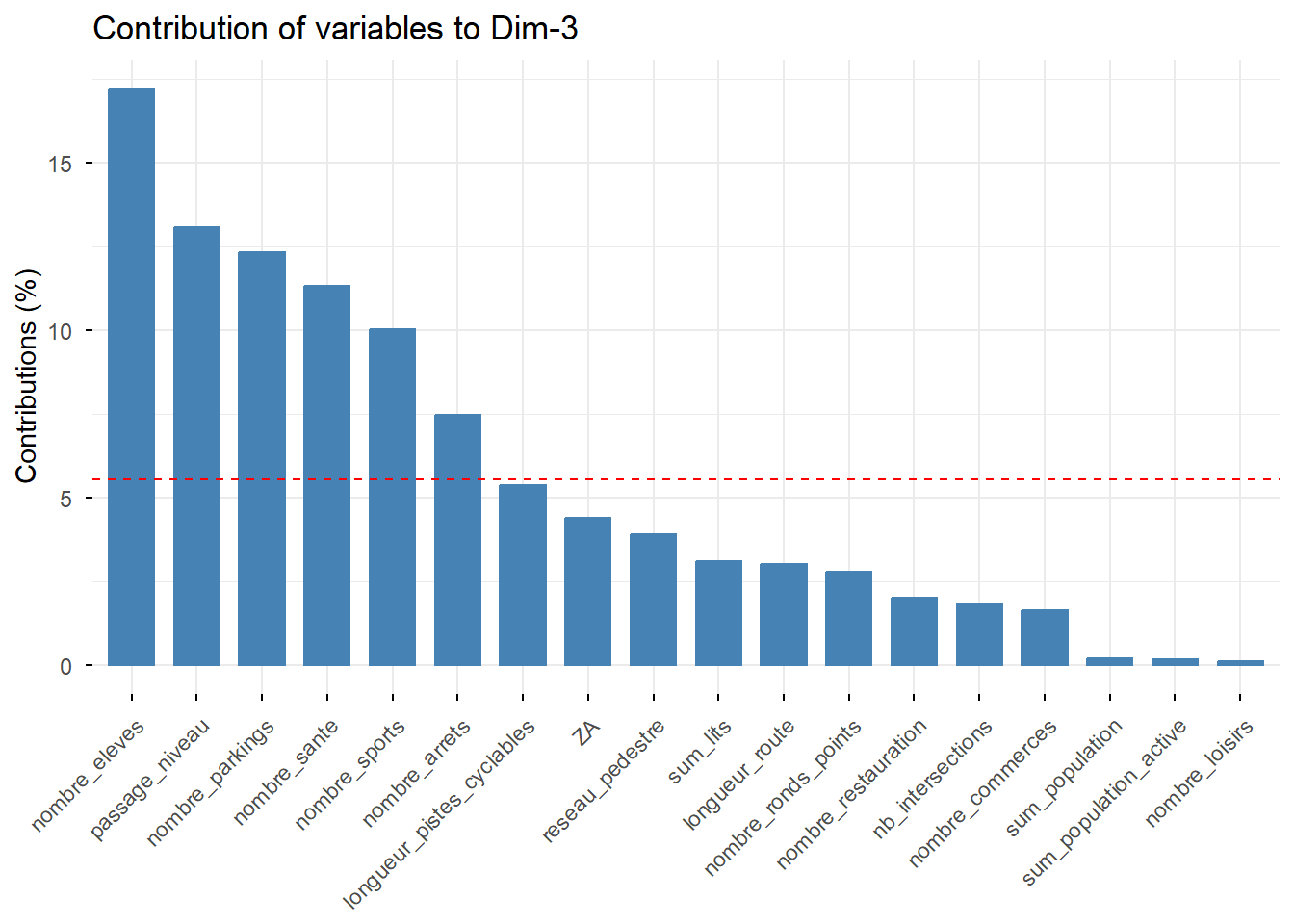
# Contribution de chaque individu aux deux premiers axes
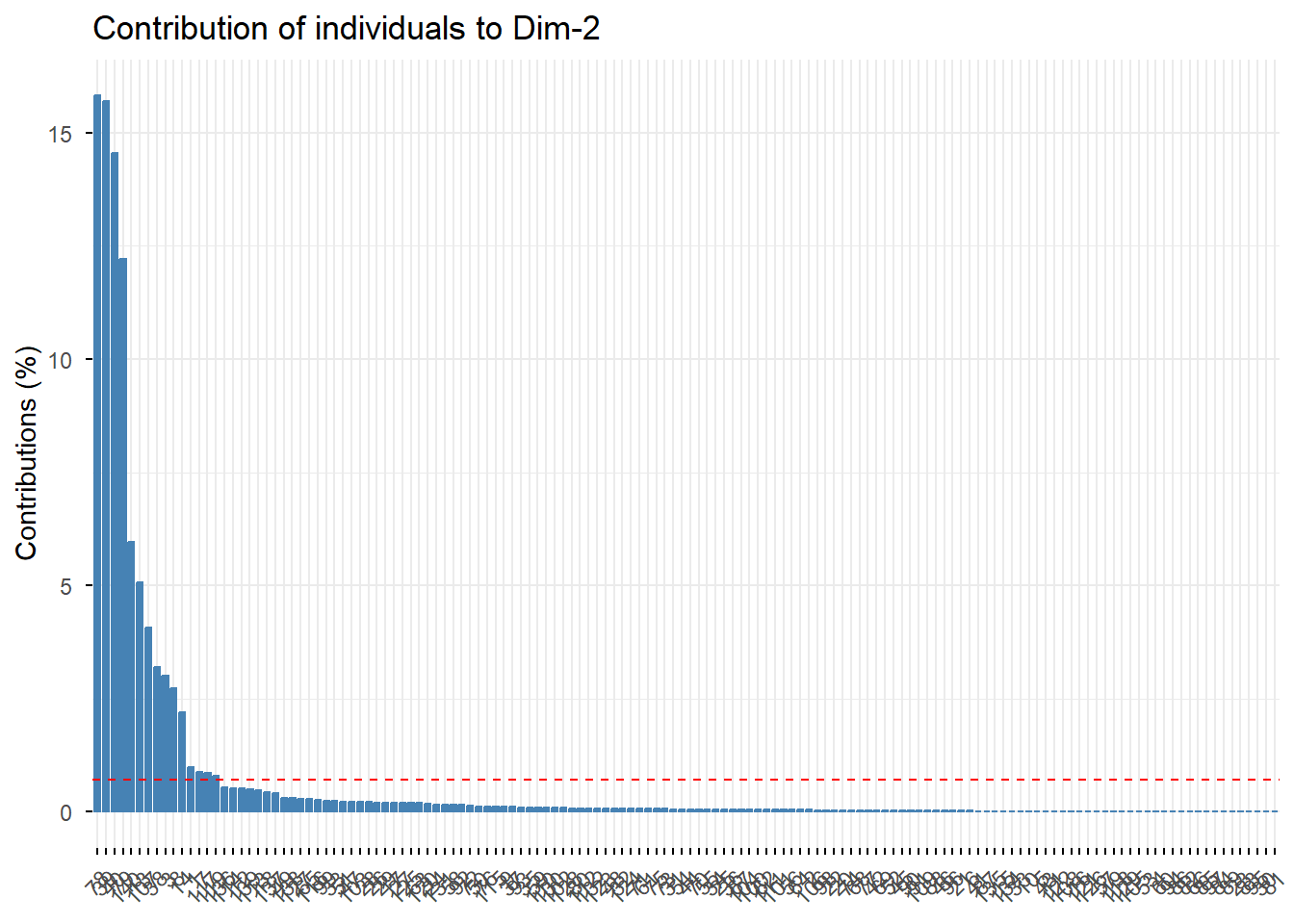
fviz_contrib(PCA, choice = "ind", axes = 1)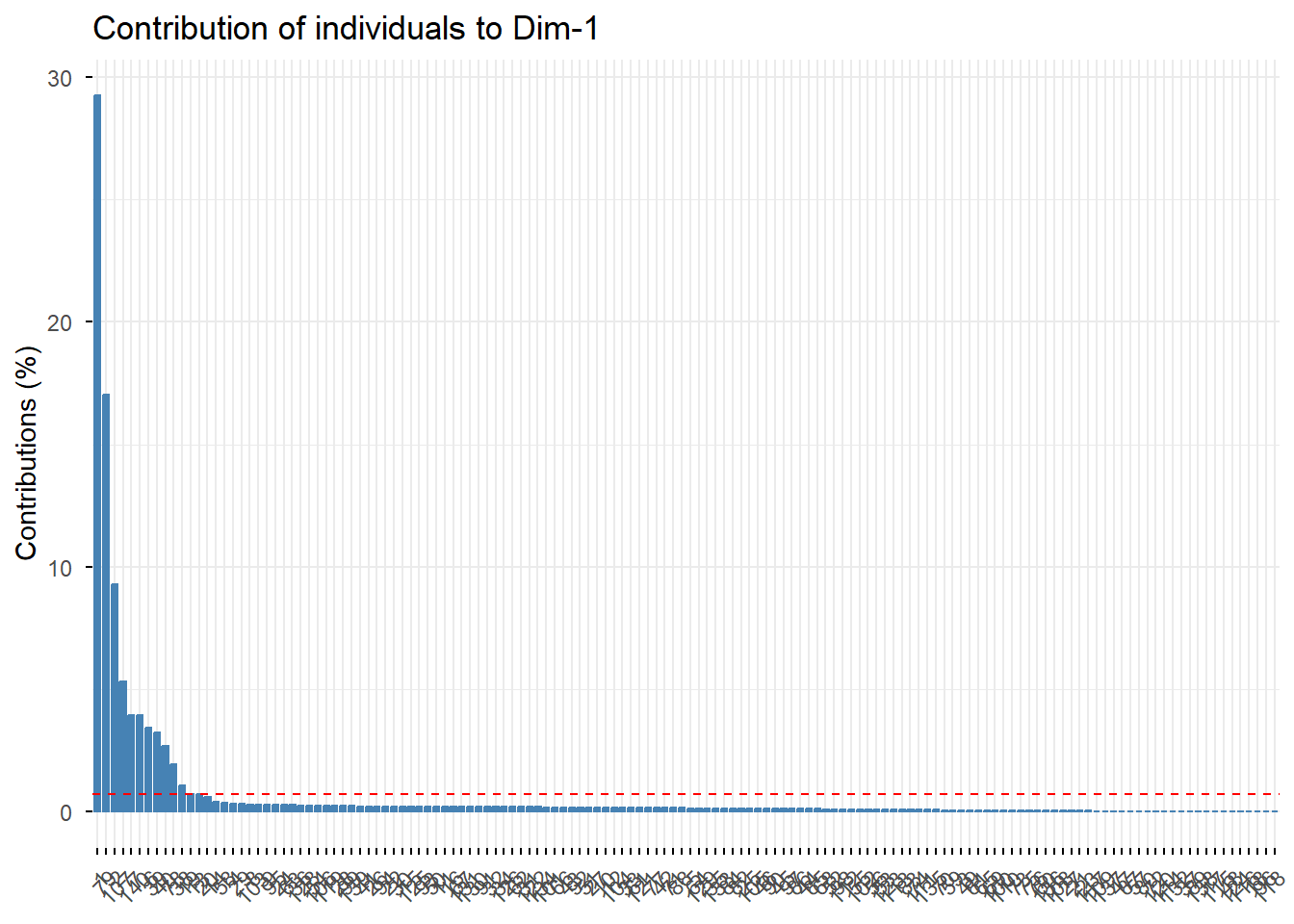
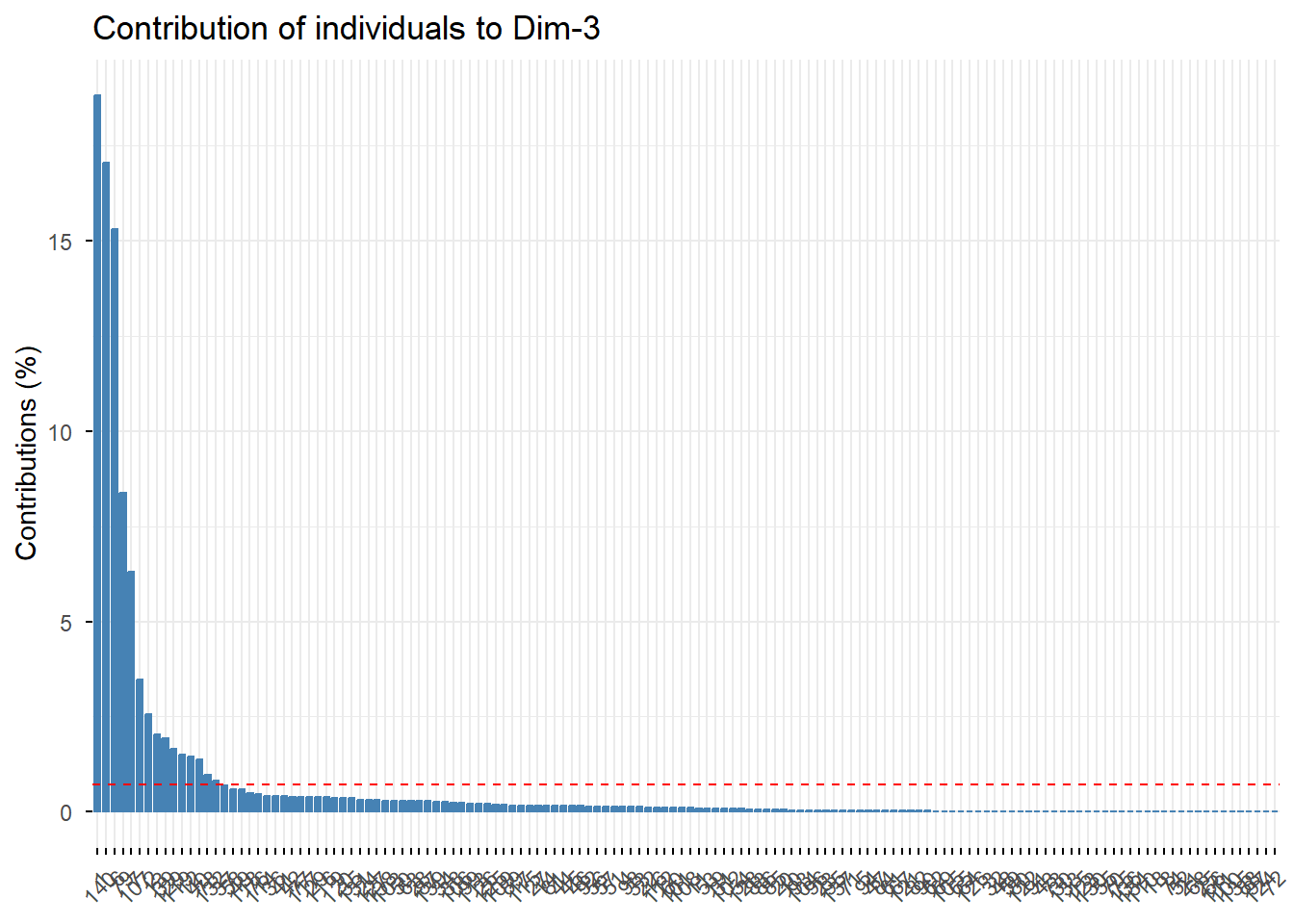
MULTINIVEAUX
Variables étudiées par niveau
NIVEAU 2 : lignes de train avec :
* nombre d’arrêts
* temps moyen du trajet entre la gare de départ et la gare d’arrivée *
longueur de la ligne
* nombre de trains par jour, à partir des données GTFS
* nombre d’incidents ? à partir de quelle base ?
NIVEAU 1 : gares avec :
* population à 10 minutes en voiture ? * infos tourisme
* arrêts de transport à proximité à 10 minutes à pied ? * commerces à 10
minutes à pied ?
* nombre d’élèves à 10 minutes à vélo ?
* zones artificielles à 10 minutes à pied ?
* passages à niveau à 10 minutes à pied ?
TABLEAU DES LIGNES FERROVIAIRES (niveau 2)
Ici je calcule le temps moyen d’un trajet entre la gare de départ et
la gare d’arrivée. Je compte également le nombre d’arrêts par
ligne.
# temps moyen pour toutes les lignes ----
# Charger les données
## Itinéraires de transport en commun. Ex : Paris Montparnasse - Toulouse Matabiau
routes <- read.csv('data/GTFS/export-ter-gtfs-last/routes.txt', header = TRUE) %>%
filter(route_type == 2) # 0 = Tram/Tramway/Train léger ; # 1 = Métro ; 2 = Rails ; 3 = Bus ; 4 = Ferry
## Trajets pour chaque ligne.
## Un trajet est une séquence de deux arrêts ou plus qui se produisent pendant une période de temps spécifique
trips <- read.csv('data/GTFS/export-ter-gtfs-last/trips.txt', header = TRUE)
## Les heures d'arrivée et de départ d'un véhicule aux arrêts pour chaque trajet.
stop_times <- read.csv('data/GTFS/export-ter-gtfs-last/stop_times.txt', header = TRUE)
# dataframe pour stocker les durées moyennes par route entre point de départ et d'arrivée
average_durations <- data.frame(route_id = character(),
average_time = numeric())
# Boucle sur chaque route_id dans routes
for(route_id_select in unique(as.character(routes$route_id))) {
# Filtre les trajets pour la route actuelle
filtered_trips <- trips %>%
filter(route_id == route_id_select)
# Extraction du nom de la route
routes_filter <- filtered_trips$route_id[1]
route_long_name <- routes %>%
filter(route_id == routes_filter)
route_long_name <- route_long_name$route_long_name
# Filtre les stop_times pour les trajets filtrés
stop_times_filtered <- stop_times %>%
filter(trip_id %in% filtered_trips$trip_id) %>%
arrange(trip_id, arrival_time) %>%
select(trip_id, stop_id, arrival_time, departure_time)
# Calculer la durée de chaque voyage
trip_durations <- stop_times_filtered %>%
group_by(trip_id) %>%
summarise(
start_time = first(departure_time),
end_time = last(arrival_time),
duration = as.numeric(hms(end_time) - hms(start_time), units = "mins")
)
# Calcule la durée moyenne pour la route actuelle
average_duration <- trip_durations %>%
summarise(average_time = mean(duration, na.rm = TRUE))
# Ajout du résultat dans le dataframe des durées moyennes
average_durations <- rbind(average_durations, data.frame(route_id = route_id_select,
route_name = route_long_name,
average_time = average_duration$average_time))
}
# Affiche les durées moyennes pour toutes les routes
head(average_durations)## route_id
## 1 FR:Line::00F7208C-CEBC-4521-A792-6EC3ABB65811:
## 2 FR:Line::0128E1D5-9183-4D58-B1CF-F5AA5A64A037:
## 3 FR:Line::0202671B-7107-429E-A37B-473C55E0254C:
## 4 FR:Line::022B77D9-D121-4DCB-B808-FB2F7931866B:
## 5 FR:Line::02534A5F-903C-454E-A24F-E6E2E23B3CBF:
## 6 FR:Line::02D330A2-2167-400E-BE91-0B5990BA287B:
## route_name average_time
## 1 Saint-Étienne - Roanne 69.86747
## 2 Marseille - Toulon - Hyeres 73.33628
## 3 Montpellier Saint-Roch - Avignon Centre 70.95122
## 4 Nantes Cholet Angers Saumur 44.59722
## 5 Ambérieu - Mâcon 48.98058
## 6 Nantes - Clisson 27.69841# nombre de stops par lignes (routes) ----
# Charger les données
## Itinéraires de transport en commun. Ex : Paris Montparnasse - Toulouse Matabiau
routes <- read.csv('data/GTFS/export-ter-gtfs-last/routes.txt', header = TRUE) %>%
filter(route_type == 2) # 0 = Tram/Tramway/Train léger ; # 1 = Métro ; 2 = Rails ; 3 = Bus ; 4 = Ferry
## Trajets pour chaque ligne
## Un trajet est une séquence de deux arrêts ou plus qui se produisent pendant une période de temps spécifique
trips <- read.csv('data/GTFS/export-ter-gtfs-last/trips.txt', header = TRUE)
## Arrêts où les véhicules prennent ou déposent les usagers.
## Définit également les stations et les entrées de station.
stops <- read.csv('data/GTFS/export-ter-gtfs-last/stops.txt', header = TRUE)
# Joindre trips à routes
trips_with_routes <- trips %>%
inner_join(routes, by = "route_id")
# Joindre stop_times à trips_with_routes
stops_with_routes <- stop_times %>%
inner_join(trips_with_routes, by = "trip_id")
stops_per_route <- stops_with_routes %>%
group_by(route_id) %>%
summarise(number_of_stops = n_distinct(stop_id))
head(stops_per_route)## # A tibble: 6 × 2
## route_id number_of_stops
## <chr> <int>
## 1 FR:Line::00F7208C-CEBC-4521-A792-6EC3ABB65811: 15
## 2 FR:Line::0128E1D5-9183-4D58-B1CF-F5AA5A64A037: 19
## 3 FR:Line::0202671B-7107-429E-A37B-473C55E0254C: 23
## 4 FR:Line::022B77D9-D121-4DCB-B808-FB2F7931866B: 12
## 5 FR:Line::02534A5F-903C-454E-A24F-E6E2E23B3CBF: 25
## 6 FR:Line::02D330A2-2167-400E-BE91-0B5990BA287B: 8# Fusion des deux data frames sur la colonne 'route_id'
merged_data <- merge(average_durations, stops_per_route, by = "route_id")
# Affichage des premières lignes du data frame fusionné
head(merged_data)## route_id
## 1 FR:Line::00F7208C-CEBC-4521-A792-6EC3ABB65811:
## 2 FR:Line::0128E1D5-9183-4D58-B1CF-F5AA5A64A037:
## 3 FR:Line::0202671B-7107-429E-A37B-473C55E0254C:
## 4 FR:Line::022B77D9-D121-4DCB-B808-FB2F7931866B:
## 5 FR:Line::02534A5F-903C-454E-A24F-E6E2E23B3CBF:
## 6 FR:Line::02D330A2-2167-400E-BE91-0B5990BA287B:
## route_name average_time number_of_stops
## 1 Saint-Étienne - Roanne 69.86747 15
## 2 Marseille - Toulon - Hyeres 73.33628 19
## 3 Montpellier Saint-Roch - Avignon Centre 70.95122 23
## 4 Nantes Cholet Angers Saumur 44.59722 12
## 5 Ambérieu - Mâcon 48.98058 25
## 6 Nantes - Clisson 27.69841 8## [1] "route_id" "route_name" "average_time" "number_of_stops"Point étape : ici j’ai donc les lignes avec leur temps moyen de trajet entre le départ et l’arrivée et le nombre d’arrêts pour chaque trajet.
TABLEAU DES GARES (niveau 1)
# création du tableau route_id, stops_id, stop_name ----
stops <- read.csv('data/GTFS/export-ter-gtfs-last/stops.txt', header = TRUE)
stop_times <- read.csv('data/GTFS/export-ter-gtfs-last/stop_times.txt', header = TRUE)
trips <- read.csv('data/GTFS/export-ter-gtfs-last/trips.txt', header = TRUE)
routes <- read.csv('data/GTFS/export-ter-gtfs-last/routes.txt', header = TRUE)
# Joindre les data frames sur 'stop_id'
joined_data <- merge(stop_times, stops, by = "stop_id")
# final_table <- joined_data %>%
# group_by(trip_id) %>%
# summarise(
# trip_id = paste(unique(trip_id), collapse = ", "),
# stops_name = paste(unique(stop_name), collapse = ", ")
# )
# Joindre les data frames sur 'trip_id'
joined_data_2 <- merge(trips, joined_data, by = "trip_id")
# final_table_2 <- joined_data_2 %>%
# group_by(trip_id) %>%
# summarise(
# trip_id = paste(unique(trip_id), collapse = ", "),
# route_id = paste(unique(route_id), collapse = ", ")
# )
# Joindre les data frames sur 'stop_id'
joined_data_3 <- merge(routes, joined_data_2, by = "route_id")
final_table <- joined_data_3 %>%
group_by(stop_id) %>%
summarise(
stop_id = paste(unique(stop_id), collapse = ", "),
route_id = paste(unique(route_id), collapse = ", "),
stop_name = paste(unique(stop_name), collapse = ", ")
)
final_table_filter <- final_table %>%
filter(grepl('Train', stop_id))Ici je recupère les ID des routes avec les ID des arrêts et leurs noms
## # A tibble: 6 × 3
## stop_id route_id stop_name
## <chr> <chr> <chr>
## 1 StopPoint:OCETrain TER-71793150 FR:Line::21B4B826-2492-4170-AC04-0B… Portbou
## 2 StopPoint:OCETrain TER-80142893 FR:Line::7BA6A09D-4D2A-4474-992B-81… Appenwei…
## 3 StopPoint:OCETrain TER-80142901 FR:Line::7BA6A09D-4D2A-4474-992B-81… Legelshu…
## 4 StopPoint:OCETrain TER-80142919 FR:Line::7BA6A09D-4D2A-4474-992B-81… Kork
## 5 StopPoint:OCETrain TER-80142927 FR:Line::7BA6A09D-4D2A-4474-992B-81… Kehl
## 6 StopPoint:OCETrain TER-80143099 FR:Line::7BA6A09D-4D2A-4474-992B-81… Offenburg# Chargement des data
# mes données sur les gares : calculs de variables pour des isoshrones 15 minutes à pied sur les 400 gares des Hauts-de-France
gares_HDF <- sf::st_read('processed_data/gares_HDR_join_region_HDF_foot_p15_20240214.gpkg')## Reading layer `gares_HDR_join_region_HDF_foot_p15_20240214' from data source
## `C:\docs\rprojects\database_sf\processed_data\gares_HDR_join_region_HDF_foot_p15_20240214.gpkg'
## using driver `GPKG'
## Simple feature collection with 393 features and 27 fields
## Geometry type: POINT
## Dimension: XY
## Bounding box: xmin: 595141.4 ymin: 6874373 xmax: 781232.5 ymax: 7108435
## Projected CRS: RGF93 v1 / Lambert-93gares_HDF <- gares_HDF %>%
rename(stop_name = ID_number)
gares_HDF_merge <- merge(gares_HDF, final_table_filter, by = "stop_name")
names(gares_HDF_merge)## [1] "stop_name" "voy_2022"
## [3] "ID" "NOM_M"
## [5] "NOM" "INSEE_REG"
## [7] "ID_number_old" "sum_population"
## [9] "sum_population_active" "sum_lits"
## [11] "longueur_route" "nb_intersections"
## [13] "reseau_pedestre" "longueur_pistes_cyclables"
## [15] "superficie_vegetation" "nombre_arrets"
## [17] "nombre_parkings" "nombre_commerces"
## [19] "nombre_sante" "nombre_loisirs"
## [21] "nombre_restauration" "nombre_sports"
## [23] "nombre_ronds_points" "nombre_eleves"
## [25] "superficie_iso" "ZA"
## [27] "passage_niveau" "stop_id"
## [29] "route_id" "geom"gares_HDF_merge_select <- gares_HDF_merge %>%
dplyr::select(stop_name,voy_2022,sum_population,sum_lits,nombre_arrets,
nombre_commerces, nombre_eleves, ZA, passage_niveau, stop_id, route_id)
head(gares_HDF_merge_select)## Simple feature collection with 6 features and 11 fields
## Geometry type: POINT
## Dimension: XY
## Bounding box: xmin: 611500.6 ymin: 6932087 xmax: 766005.6 ymax: 7003747
## Projected CRS: RGF93 v1 / Lambert-93
## stop_name voy_2022 sum_population sum_lits nombre_arrets nombre_commerces
## 1 Abancourt 71517 1122 0 23 0
## 2 Abbeville 841557 22895 171 9 66
## 3 Achiet 80648 1281 0 19 2
## 4 Albert 524871 9814 360 20 28
## 5 Amiens 6004673 137790 1796 79 94
## 6 Amifontaine 15468 390 0 9 0
## nombre_eleves ZA passage_niveau stop_id
## 1 0 960423.8 4 StopPoint:OCETrain TER-87313759
## 2 0 1387238.6 0 StopPoint:OCETrain TER-87317362
## 3 0 1455085.8 0 StopPoint:OCETrain TER-87342048
## 4 678 1611076.5 0 StopPoint:OCETrain TER-87313072
## 5 4109 1867851.2 0 StopPoint:OCETrain TER-87313874
## 6 0 1058629.1 0 StopPoint:OCETrain TER-87171744
## route_id
## 1 FR:Line::7BDE293E-0D29-48A4-8978-8ADB3FFEA340:, FR:Line::A16522A1-3A9D-406B-B7AB-12E318E7CC92:, FR:Line::A8CBE20D-E000-4EEC-A4EE-F928AD249687:, FR:Line::B2E5B266-DAE7-4C0A-ABA0-B46411FB2CAA:, FR:Line::C6FA7EBE-4D15-41AC-AAFC-6B62BA46E49E:, FR:Line::DD461A4B-557A-4303-B639-AED4F7A5141B:, FR:Line::E0C5BF51-53A3-4542-B417-3AFE4D5EA545:
## 2 FR:Line::4B0DFE2B-138B-455F-BCEF-0B57A660A95F:, FR:Line::965C0279-4764-4FEA-B29B-363968EA28CE:, FR:Line::cf0d9ce8-bf4e-448e-8bf0-6c965a95c788:, FR:Line::D77B2111-D576-48D5-878E-5D6C094D611A:
## 3 FR:Line::7BB51D2B-5268-45E9-AEEE-1F1053DE381C:, FR:Line::7BDE293E-0D29-48A4-8978-8ADB3FFEA340:, FR:Line::B2E5B266-DAE7-4C0A-ABA0-B46411FB2CAA:, FR:Line::E597DAD9-42BF-4927-BEDB-0B05091BCBBE:
## 4 FR:Line::7BB51D2B-5268-45E9-AEEE-1F1053DE381C:, FR:Line::7BDE293E-0D29-48A4-8978-8ADB3FFEA340:, FR:Line::B2E5B266-DAE7-4C0A-ABA0-B46411FB2CAA:, FR:Line::D77B2111-D576-48D5-878E-5D6C094D611A:, FR:Line::E597DAD9-42BF-4927-BEDB-0B05091BCBBE:
## 5 FR:Line::4B0DFE2B-138B-455F-BCEF-0B57A660A95F:, FR:Line::53D6728B-4D88-418C-823F-F3E5B975E9D6:, FR:Line::74E36C89-DC6A-4CE9-A1C7-CC8552AE882C:, FR:Line::7BB51D2B-5268-45E9-AEEE-1F1053DE381C:, FR:Line::7BDE293E-0D29-48A4-8978-8ADB3FFEA340:, FR:Line::8519D738-1A3F-477E-A18B-116B8863F0F8:, FR:Line::965C0279-4764-4FEA-B29B-363968EA28CE:, FR:Line::9F35A2B3-4B24-4076-A960-83E359C90C1D:, FR:Line::A8CBE20D-E000-4EEC-A4EE-F928AD249687:, FR:Line::B2E5B266-DAE7-4C0A-ABA0-B46411FB2CAA:, FR:Line::BA37A6D8-F8EA-4672-8077-B6A6CA91A26F:, FR:Line::C6FA7EBE-4D15-41AC-AAFC-6B62BA46E49E:, FR:Line::cf0d9ce8-bf4e-448e-8bf0-6c965a95c788:, FR:Line::D77B2111-D576-48D5-878E-5D6C094D611A:, FR:Line::DD461A4B-557A-4303-B639-AED4F7A5141B:, FR:Line::E27CA8B0-68E6-43FB-BE1B-B0388CDA1008:, FR:Line::E597DAD9-42BF-4927-BEDB-0B05091BCBBE:
## 6 FR:Line::93676b4d-70bb-42ae-a4ad-fade138a46c4:
## geom
## 1 POINT (611500.6 6954704)
## 2 POINT (615814.8 7001062)
## 3 POINT (684265.1 7003747)
## 4 POINT (674493.3 6989720)
## 5 POINT (650564.5 6977107)
## 6 POINT (766005.6 6932087)## [1] "stop_name" "voy_2022" "sum_population" "sum_lits"
## [5] "nombre_arrets" "nombre_commerces" "nombre_eleves" "ZA"
## [9] "passage_niveau" "stop_id" "route_id" "geom"ICI je fusionne mes données avec le tableaux GTFS des stop name
# Fusion des tableaux de niveau 1 et 2 ----
gares_HDF_merge_select_fusion <- merge(gares_HDF_merge_select,
merged_data,
by = 'route_id')
head(gares_HDF_merge_select_fusion)## Simple feature collection with 6 features and 14 fields
## Geometry type: POINT
## Dimension: XY
## Bounding box: xmin: 682055.4 ymin: 7002663 xmax: 767913 ymax: 7049370
## Projected CRS: RGF93 v1 / Lambert-93
## route_id stop_name voy_2022
## 1 FR:Line::11D73E7F-3314-4000-B93A-A4781C56C041: Leval 2955
## 2 FR:Line::11D73E7F-3314-4000-B93A-A4781C56C041: Avesnelles 4532
## 3 FR:Line::11D73E7F-3314-4000-B93A-A4781C56C041: Dompierre 1695
## 4 FR:Line::11D73E7F-3314-4000-B93A-A4781C56C041: Saint-Hilaire 21
## 5 FR:Line::18E717A0-950C-40A2-8F27-98A8EE8ADD20: Cuinchy 34787
## 6 FR:Line::18E717A0-950C-40A2-8F27-98A8EE8ADD20: Salomé 10248
## sum_population sum_lits nombre_arrets nombre_commerces nombre_eleves
## 1 11304 0 10 0 0
## 2 6823 25 10 2 565
## 3 1690 0 10 0 0
## 4 4990 0 6 0 0
## 5 9077 13 60 3 0
## 6 6612 0 45 1 0
## ZA passage_niveau stop_id
## 1 1190081.9 4 StopPoint:OCETrain TER-87295790
## 2 1333134.5 1 StopPoint:OCETrain TER-87295725
## 3 912603.3 0 StopPoint:OCETrain TER-87295774
## 4 918654.4 1 StopPoint:OCETrain TER-87297531
## 5 1622946.6 1 StopPoint:OCETrain TER-87342410
## 6 993264.7 1 StopPoint:OCETrain TER-87342451
## route_name average_time number_of_stops
## 1 Aulnoye - Aymeries - Hirson 41.94118 14
## 2 Aulnoye - Aymeries - Hirson 41.94118 14
## 3 Aulnoye - Aymeries - Hirson 41.94118 14
## 4 Aulnoye - Aymeries - Hirson 41.94118 14
## 5 Lille Flandres - Don-Sainghin - Béthune 61.02632 18
## 6 Lille Flandres - Don-Sainghin - Béthune 61.02632 18
## geom
## 1 POINT (759823.6 7009919)
## 2 POINT (767913 7002663)
## 3 POINT (762334.8 7005671)
## 4 POINT (765420.2 7004128)
## 5 POINT (682055.4 7047216)
## 6 POINT (688399.3 7049370)Je fusionne le tableau du niveau 1 des gares (gares_HDF_merge_select) et du niveau 2 des lignes (merged_data)
MODELE MULTINIVEAUX
Je souhaite comprendre les variables qui influencent le nombre de voyageurs des gares en 2022.
# modèle multi-niveaux
# Modèle de régression multiniveaux
model <- lme4::lmer(voy_2022 ~ scale(sum_population) + scale(sum_lits) + scale(nombre_arrets) + scale(nombre_commerces) + scale(nombre_eleves) + scale(ZA) + scale(passage_niveau) + scale(average_time) + scale(number_of_stops) +
(1 | route_id), # prise en compte des variables des routes comme point de départ avant même de prendre en compte les variables sur les gares
data = gares_HDF_merge_select_fusion)
# Afficher le résumé du modèle
summary(model)## Linear mixed model fit by REML ['lmerMod']
## Formula:
## voy_2022 ~ scale(sum_population) + scale(sum_lits) + scale(nombre_arrets) +
## scale(nombre_commerces) + scale(nombre_eleves) + scale(ZA) +
## scale(passage_niveau) + scale(average_time) + scale(number_of_stops) +
## (1 | route_id)
## Data: gares_HDF_merge_select_fusion
##
## REML criterion at convergence: 2211
##
## Scaled residuals:
## Min 1Q Median 3Q Max
## -2.2513 -0.3671 -0.0971 0.1829 6.0432
##
## Random effects:
## Groups Name Variance Std.Dev.
## route_id (Intercept) 2.299e+09 47947
## Residual 4.103e+09 64056
## Number of obs: 96, groups: route_id, 30
##
## Fixed effects:
## Estimate Std. Error t value
## (Intercept) 36624 11345 3.228
## scale(sum_population) -77130 53273 -1.448
## scale(sum_lits) 58208 52656 1.105
## scale(nombre_arrets) -7389 10183 -0.726
## scale(nombre_commerces) 22045 11692 1.885
## scale(nombre_eleves) -14341 9507 -1.508
## scale(ZA) 28886 10383 2.782
## scale(passage_niveau) 6547 7852 0.834
## scale(average_time) 21063 13856 1.520
## scale(number_of_stops) -12582 12978 -0.969
##
## Correlation of Fixed Effects:
## (Intr) scl(sm_p) scl(sm_l) scl(nmbr_r) scl(nmbr_c) scl(nmbr_l)
## scl(sm_ppl) -0.009
## scl(sm_lts) 0.013 -0.984
## scl(nmbr_r) 0.017 -0.164 0.166
## scl(nmbr_c) 0.021 0.195 -0.263 -0.208
## scl(nmbr_l) -0.006 -0.201 0.241 -0.012 -0.478
## scale(ZA) -0.017 -0.269 0.256 -0.164 -0.354 -0.060
## scl(pssg_n) -0.009 0.034 0.006 -0.121 0.012 0.074
## scl(vrg_tm) 0.045 0.100 -0.082 0.104 0.053 0.018
## scl(nmbr__) 0.015 0.053 -0.042 0.064 -0.039 0.014
## sc(ZA) scl(p_) scl(v_)
## scl(sm_ppl)
## scl(sm_lts)
## scl(nmbr_r)
## scl(nmbr_c)
## scl(nmbr_l)
## scale(ZA)
## scl(pssg_n) -0.139
## scl(vrg_tm) -0.059 0.081
## scl(nmbr__) -0.046 0.009 -0.467# R2
# Installer et charger le package MuMIn si nécessaire
if (!requireNamespace("MuMIn", quietly = TRUE)) install.packages("MuMIn")## Registered S3 methods overwritten by 'MuMIn':
## method from
## nobs.multinom broom
## nobs.fitdistr broom## R2m R2c
## [1,] 0.181769 0.4755837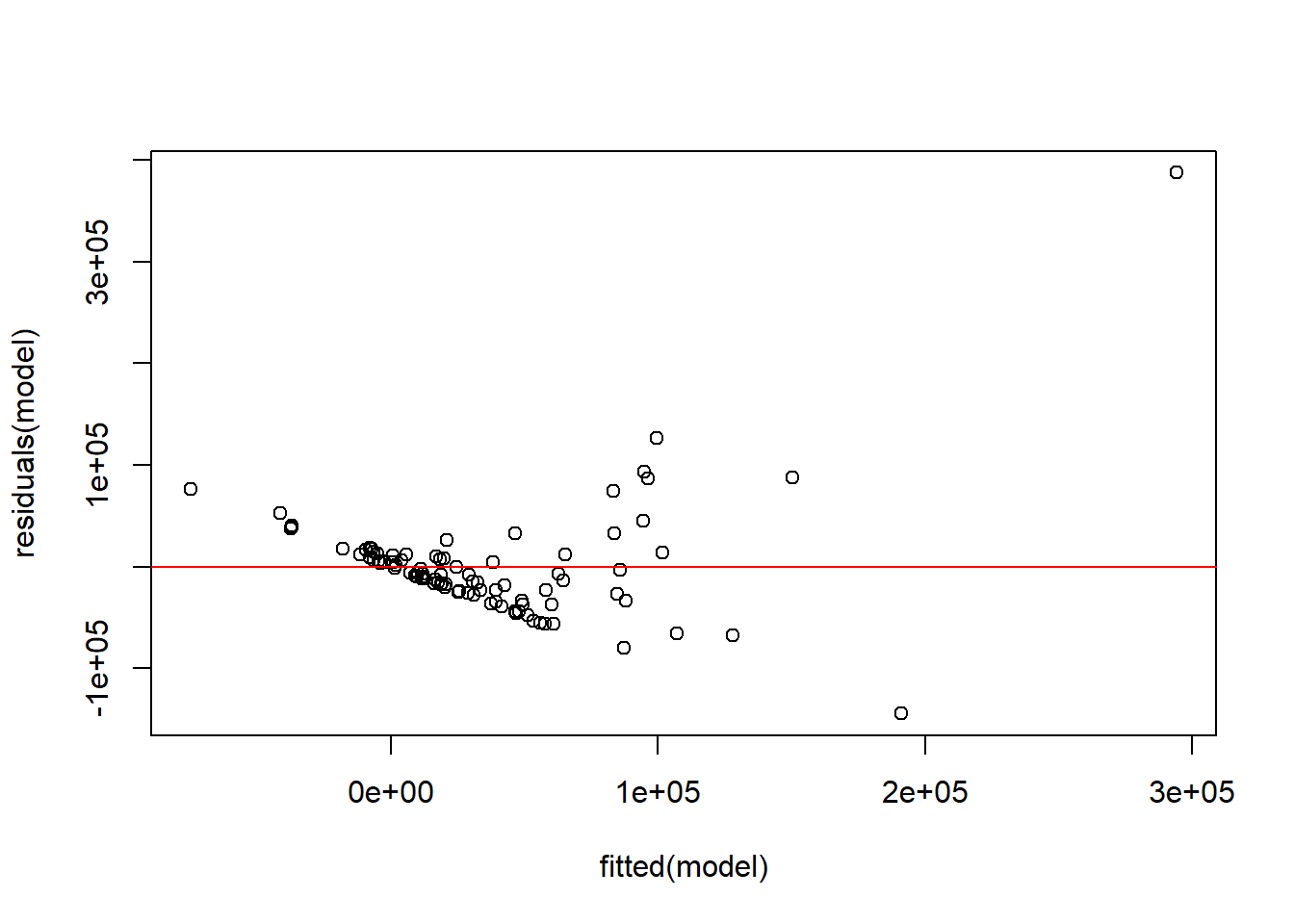
# Histogramme des résidus pour vérifier la normalité
hist(residuals(model), breaks = "Scott", main = "Histogramme des Résidus", xlab = "Résidus")
# QQ-plot des résidus
# Dans un QQ-plot, les points devraient se situer approximativement le long de la ligne rouge
# si les résidus suivent une distribution normale.
qqnorm(residuals(model))
qqline(residuals(model), col = "red")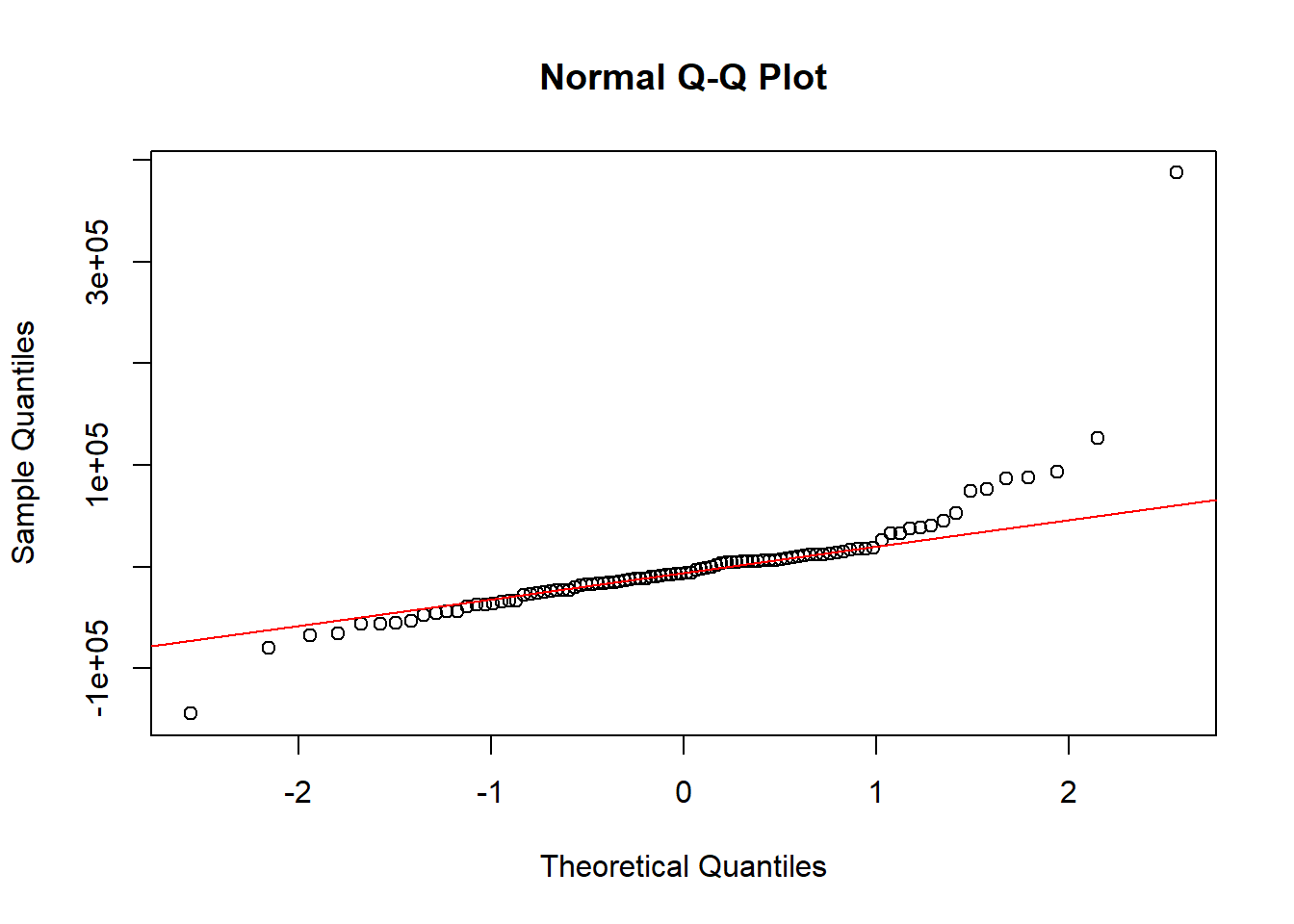
TRANSFORMATION
- La standardisation (scores z) se concentre sur la
reconfiguration des données pour qu’elles aient une moyenne de 0 et un
écart-type de 1, rendant ainsi la distribution des données standardisée
en termes d’unités d’écart-type. Elle est utile pour comparer des scores
entre différentes échelles et est souvent préférée dans les analyses qui
supposent une distribution normale des données.
- La normalisation Min-Max redimensionne les données
dans un intervalle fixe, souvent [0, 1], en ajustant chaque valeur selon
les valeurs minimales et maximales de l’ensemble de données, ce qui est
utile pour les modèles sensibles aux variations d’échelle entre les
variables. Elle est particulièrement utile pour les algorithmes
sensibles aux échelles des variables, comme les algorithmes basés sur
les distances. La normalisation Min-Max est souvent utilisée dans les
contextes où l’uniformité de l’échelle entre les variables est
cruciale.
- La normalisation par la valeur maximale ajuste les
données selon la plus grande valeur absolue de l’ensemble de données,
rendant toutes les valeurs relatives à cette valeur maximale, ce qui est
une approche simplifiée de mise à l’échelle par rapport à une valeur de
référence unique. Elle est similaire à la normalisation Min-Max mais se
concentre uniquement sur le redimensionnement par rapport à la valeur
maximale de chaque variable. Si toutes les valeurs sont positives, les
données varient entre 0 et 1. La normalisation par la valeur maximale
peut être préférée pour sa simplicité et lorsque la dominance de la
valeur maximale est significative pour l’analyse.